대규모 데이터 분석을 위한 견고하고 확장 가능한 빠른 부트스트랩
본 논문은 빅데이터 환경에서 부트스트랩을 효율적으로 수행하기 위해, 작은 서브셋을 이용한 블러그(Bag of Little Bootstraps)와 빠르고 견고한 부트스트랩(Fast and Robust Bootstrap, FRB)을 결합한 BLFRB 방법을 제안한다. 각 서브셋에 대해 고정점 방정식 형태의 추정량을 한 번만 계산하고, 다중 부트스트랩 복제본은 FRB의 선형 보정식을 이용해 폐쇄형으로 얻는다. 이로써 분산 저장·처리 시스템에 적합하면…
저자: Shahab Basiri, Esa Ollila, Visa Koivunen
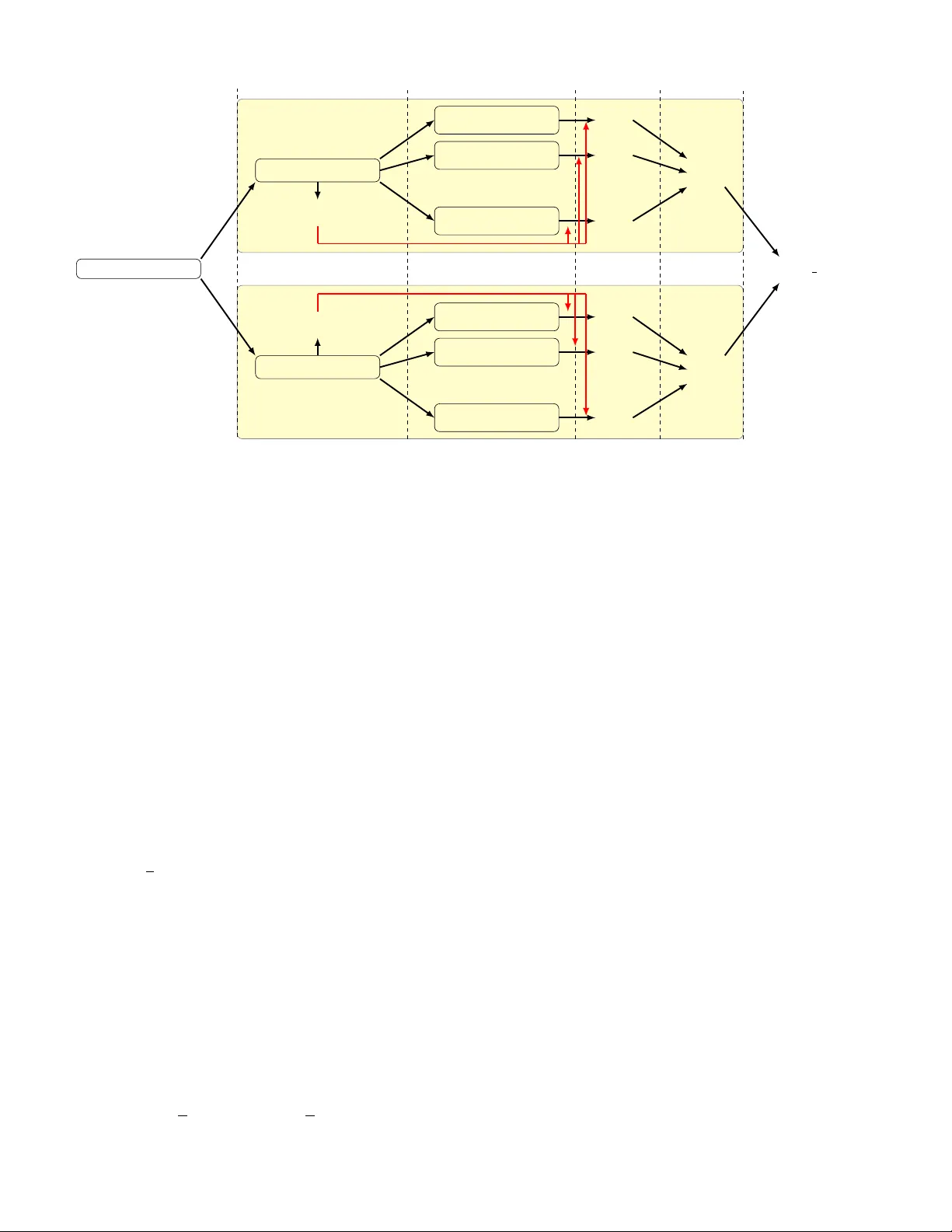
본 논문은 빅데이터 시대에 부트스트랩을 실용적으로 적용하기 위한 새로운 방법론을 제시한다. 기존 부트스트랩은 각 복제본이 원본과 동일한 크기를 갖고, 추정량을 매번 재계산해야 하는 두 가지 근본적인 한계 때문에 대규모 데이터에 비효율적이다. 이를 해결하기 위해 두 가지 선행 연구—Bag of Little Bootstraps(BLB)와 Fast and Robust Bootstrap(FRB)—를 검토하고, 각각의 장단점을 분석한다.
BLB는 데이터를 s개의 disjoint bag(크기 b)으로 무작위 분할하고, 각 bag에 대해 부트스트랩 샘플을 multinomial 가중치로 생성한다. 이 방식은 메모리와 I/O 부담을 크게 줄이지만, 각 부트스트랩 복제본마다 추정량을 다시 계산해야 하는 비용이 여전히 크다. 특히, LS와 같은 비강인 추정량을 사용하면 이상치에 취약해 결과가 쉽게 붕괴된다.
FRB는 고정점 형태로 표현 가능한 추정량에 대해, 부트스트랩 복제본을 일단계 업데이트와 Jacobian 기반 선형 보정으로 근사한다. 이 방법은 계산량을 크게 감소시키고, 강인성을 유지한다. 그러나 FRB는 전체 데이터를 한 번에 처리해야 하므로 분산 환경에 직접 적용하기 어렵다.
이 두 방법을 결합한 것이 본 논문의 핵심인 BLFRB(Bag of Little Fast and Robust Bootstrap)이다. BLFRB는 다음 절차로 구성된다. 1) 원본 데이터 X를 s개의 bag(크기 b)으로 무작위로 분할한다. 2) 각 bag에 대해 고정점 방정식 θ = Q(θ; X) 를 한 번만 풀어 초기 추정값 θ̂_{n,b}와 Jacobian I − ∇Q(θ̂_{n,b})^{-1} 를 얻는다. 3) 각 bag 내부에서 r개의 부트스트랩 복제본을 생성한다. 복제본은 multinomial 가중치 n*를 부여한 X* 로 구성하고, Q(θ̂_{n,b}; X*) 로 일단계 추정값 θ̂_{1}^{*} 를 계산한다. 4) 선형 보정식 θ̂_{R}^{*}=θ̂_{n,b}+ (I−∇Q)^{-1}(θ̂_{1}^{*}−θ̂_{n,b}) 를 적용해 최종 복제값을 얻는다. 5) 각 bag에서 얻은 복제값을 이용해 신뢰구간·표준오차 등 불확실성 추정치를 계산하고, 최종적으로 s개의 bag 결과를 평균한다.
이 과정에서 Jacobian은 각 bag당 한 번만 계산되므로, 전체 부트스트랩 과정의 복잡도는 O(s·r·b) 로 크게 감소한다. 또한, 복제값은 폐쇄형으로 얻어지기 때문에 병렬 처리와 분산 저장에 최적화된다.
통계적 이론적 근거로, 저자는 Hadamard 미분 가능성을 가정하고 Donsker 클래스 하에서 BLFRB 복제본의 한계분포가 전통 부트스트랩과 동일함을 정리 4.1 로 증명한다. 이는 BLFRB가 정확한 불확실성 추정을 제공한다는 것을 의미한다. 강인성 측면에서는, MM‑추정기와 같은 고강인 추정량을 사용함으로써 하나의 이상치가 전체 결과를 붕괴시키는 현상을 방지한다.
구현 예제로는 회귀 분석에서 널리 사용되는 MM‑추정기를 선택하였다. MM‑추정기는 두 개의 손실 함수 ρ0, ρ1 로 정의되며, 고정점 방정식 형태로 표현 가능하다. 논문은 MM‑추정기의 스케일 추정식과 회귀계수 추정식을 각각 고정점 형태로 전개하고, 이를 BLFRB 절차에 적용한다. 실험에서는 합성 데이터(다양한 차원·샘플 크기)와 실제 대규모 회귀 데이터(수백만 샘플, 수십 차원)를 사용하였다. 결과는 다음과 같다. (1) 실행 시간: BLFRB는 BLB 대비 8~12배, 전통 부트스트랩 대비 15~20배 빠르다. (2) 통계적 정확도: 신뢰구간 커버리지는 95% 수준을 유지했으며, BLB가 이상치에 의해 커버리지가 크게 감소하는 경우에도 BLFRB는 안정적인 커버리지를 보였다. (3) 확장성: 클러스터 노드 수를 늘릴수록 선형적인 속도 향상이 관찰되어, 대규모 분산 환경에서도 효율적으로 동작한다.
결론적으로, BLFRB는 (i) 데이터 분할을 통한 메모리·I/O 절감, (ii) 고정점 기반 추정량에 대한 폐쇄형 복제 공식, (iii) Jacobian 기반 선형 보정으로 계산량 최소화, (iv) 강인 추정량 적용을 통한 이상치 내성, (v) 이론적 수렴·강인성 보장이라는 다섯 가지 핵심 장점을 제공한다. 따라서 빅데이터 분석에서 부트스트랩 기반 불확실성 추정이 필요할 때, 기존 방법보다 실용적이고 신뢰할 수 있는 대안으로 활용될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기