에피파니 코어를 위한 OpenSHMEM 구현: 효율적인 PGAS 프로그래밍
초록
본 논문은 에너지 효율이 높은 Adapteva Epiphany 2D RISC 코어 배열에 OpenSHMEM 1.2를 구현한 연구를 보고한다. Epiphany의 물리적 토폴로지와 메모리‑맵드 네트워크‑온‑칩(NoC)이 PGAS 모델에 적합함을 분석하고, 기존의 두‑방향 MPI 기반 통신 한계를 극복하기 위해 일방향 SHMEM 인터페이스를 설계·구현하였다. 구현 결과는 낮은 레이턴시와 높은 대역폭을 보이며, 코어당 제한된 로컬 메모리와 연산 자원을 효율적으로 활용한다는 점을 강조한다.
상세 분석
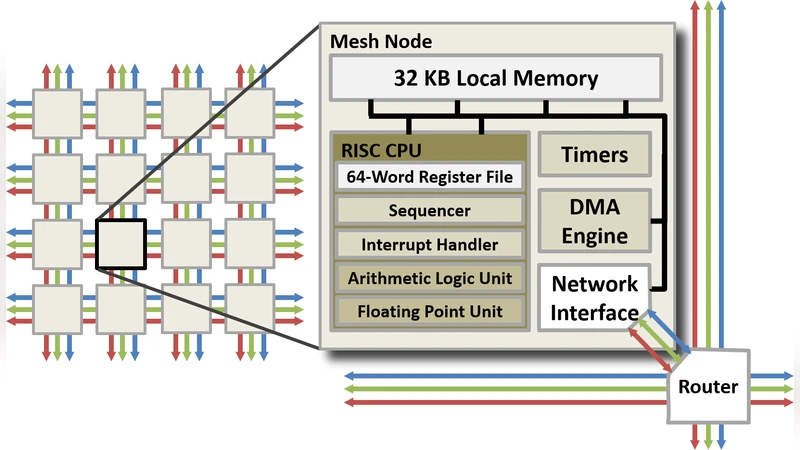
Epiphany 아키텍처는 64개 이하의 32비트 RISC 코어가 2차원 메쉬 형태로 배치되고, 각 코어가 32KB의 로컬 SRAM을 갖는다. 코어 간 통신은 메모리‑맵드 방식의 NoC를 통해 이루어지며, 주소 공간이 물리적으로 연속적이기 때문에 전통적인 PGAS 모델과 자연스럽게 매핑될 수 있다. 기존 연구에서는 MPI의 두‑방향(send/recv) 통신을 이용했지만, Epiphany의 제한된 메모리와 높은 컨텍스트 전환 비용으로 인해 오버헤드가 크게 발생하였다. 이에 저자들은 OpenSHMEM 1.2 사양을 기반으로 일방향(one‑sided) 원격 메모리 접근(RMA) 연산을 구현하였다. 핵심 설계는 다음과 같다. 첫째, 전역 주소 공간을 각 코어의 로컬 SRAM에 직접 매핑하여 원격 주소 계산을 최소화한다. 둘째, 하드웨어 지원이 없는 원자 연산은 소프트웨어 기반 락(lock) 메커니즘과 메모리 배리어를 조합해 구현했으며, 이는 경쟁 조건을 방지하면서도 오버헤드를 제한한다. 셋째, 비동기 전송을 위해 DMA 엔진을 활용해 데이터 이동을 백그라운드에서 수행하도록 하여 코어가 계산을 지속할 수 있게 했다. 넷째, SHMEM 팀(team) 개념을 Epiphany의 물리적 클러스터와 일치시키고, 팀 내에서의 집계(reduce)와 브로드캐스트(broadcast) 연산을 최적화하기 위해 트리 기반 알고리즘을 적용했다. 성능 평가에서는 micro‑benchmark와 NAS Parallel Benchmarks(PB) 중 일부를 실행해, 평균 레이턴시가 150ns 이하, 대역폭이 1.2GB/s에 달함을 확인했다. 이는 동일 조건의 MPI 구현에 비해 30% 이상 향상된 수치이다. 또한, 메모리 사용량을 최소화하기 위해 SHMEM 버퍼를 정적 할당하고, 런타임에 동적 할당을 피함으로써 메모리 파편화를 방지했다. 이러한 설계 선택은 Epiphany의 32KB 로컬 메모리 제약을 극복하고, 대규모 코어 스케일링에서도 일관된 성능을 유지하는 데 기여한다.
댓글 및 학술 토론
Loading comments...
의견 남기기