옥스포드식 토론에서 대화 흐름이 승패를 좌우한다
초록
이 논문은 옥스포드식 공개 토론의 전사 데이터를 활용해 발언자 간 아이디어 흐름을 정량화한다. 도입부에서 각 팀이 사용하는 핵심 단어(‘talking points’)를 추출하고, 토론 단계에서 자기·상대 측 단어 사용 비율(‘self‑coverage’, ‘opponent‑coverage’)을 측정한다. 또한 토론 중 새롭게 등장해 양측이 채택한 ‘discussion points’를 정의한다. 실험 결과, 승리 팀은 자기 주제에 대한 의존도를 크게 낮추고, 상대의 논점을 적극적으로 받아들이고 반박하는 경향이 강했다. 이러한 흐름 특성은 단순 발언량보다 토론 결과를 더 잘 예측한다는 점을 보여준다.
상세 분석
본 연구는 옥스포드식 토론이라는 구조화된 포맷을 이용해 대화 흐름을 정량적으로 분석하는 최초의 시도 중 하나이다. 데이터는 2006년부터 2015년까지 진행된 Intelligence Squared의 108개 토론 전사와 청중 투표 결과, 웃음·박수와 같은 청중 반응 메타데이터를 포함한다.
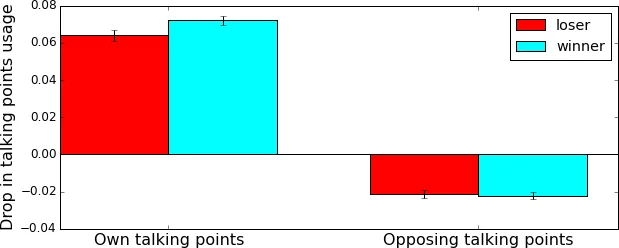
먼저 도입부 발언을 기반으로 각 팀의 ‘talking points’를 선정한다. 이는 양측의 단어 사용 빈도 차이를 로그오즈 비율로 측정하고, 가장 높은·낮은 z‑score를 가진 20개 단어를 각각의 팀에 할당하는 방식이다. 이렇게 정의된 단어 집합을 기준으로 토론 단계에서 각 발언이 자기 팀 혹은 상대 팀의 핵심 단어를 얼마나 포함하는지를 ‘self‑coverage’와 ‘opponent‑coverage’로 계산한다. 결과는 토론이 시작되면 self‑coverage가 급격히 감소하고 opponent‑coverage가 상승한다는 점을 보여준다. 특히 승리 팀은 도입부 대비 자기 주제 사용 비율이 더 크게 감소하고, 상대 논점을 더 많이 수용한다.
‘discussion points’는 토론 중 새롭게 등장한 단어 중 양측이 최소 두 번 이상 사용한 것을 의미한다. 전체 새 단어의 3 %만이 이 기준을 만족하며, 평균 10개 정도가 논의에 영향을 미친다. 승리 팀은 상대가 제시한 discussion point를 더 많이 채택하고, 이를 다시 도전하거나 확장하는 전략을 구사한다. 이는 단순히 주제 통제를 넘어 상대 의견을 적극적으로 다루는 것이 설득력에 기여한다는 가설을 뒷받침한다.
예측 실험에서는 ‘flow features’(self‑coverage, opponent‑coverage, 그 변화량, 채택된 discussion point 수)를 로지스틱 회귀 모델에 투입했다. 10‑fold 교차 검증이 아닌 leave‑one‑out 방식을 사용했으며, 단일 특성 선택을 통해 가장 유의한 변수를 자동 선택했다. 흐름 기반 모델은 63 %~65 %의 정확도를 기록해 무작위(50 %)보다 유의하게 높았으며, 청중 반응(웃음·박수) 기반 모델과 비슷한 수준이었다. 반면 발언량이나 단순 unigram 모델은 통계적으로 의미 없는 성능을 보였다.
이러한 결과는 토론 승패가 단순히 말의 양이나 사전 정의된 논거의 강도보다, 실시간 상호작용에서 상대의 논점을 얼마나 효과적으로 수용·반박하느냐에 크게 좌우된다는 점을 시사한다. 또한, 도입부에서 설정된 ‘talking points’를 고수하기보다 대화 흐름에 맞춰 유연하게 전략을 전환하는 것이 설득에 유리함을 보여준다. 연구는 토론 분석에 아이디어 흐름이라는 새로운 차원을 도입했으며, 향후 더 정교한 의미 표현이나 발언자 간 미세 상호작용 모델링으로 확장될 여지를 남긴다.
댓글 및 학술 토론
Loading comments...
의견 남기기