네덜란드 억양 위치 추정 프로젝트
본 논문은 네덜란드 전역의 억양을 기록·분석하기 위해 개발된 스마트폰 앱 기반 데이터 수집 프로젝트 “Sprekend Nederland”을 소개한다. 억양을 단순 분류가 아니라 화자의 지리·사회적 이동 이력을 반영한 “억양 위치”(Accent Location) 개념으로 정의하고, 이를 자동화하기 위한 모델링·평가 방안을 논의한다.
저자: David A. van Leeuwen, Rosemary Orr
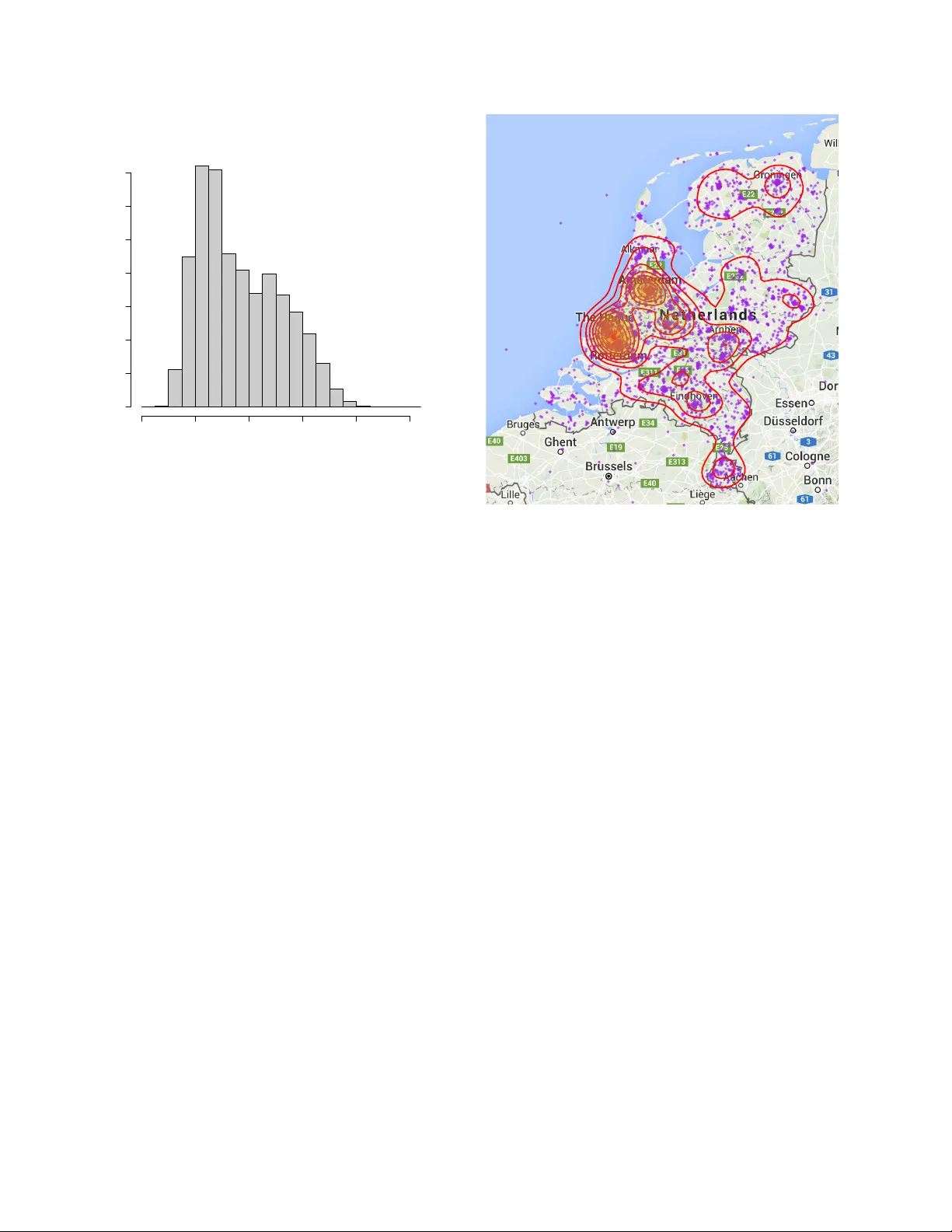
본 논문은 네덜란드 전역의 억양 다양성을 체계적으로 기록하고, 이를 기반으로 화자의 출신지와 이동 이력을 추정하는 “자동 억양 위치(Auto Accent Location)” 과제를 정의한다. 서론에서는 기존 억양 인식이 주로 미국 TIMIT, NIST LRE 등에서 정의된 고정된 지역 클래스를 구분하는 분류 문제에 머물러 있었으며, 인간 청취자가 실제로는 “이 사람은 어디에서 왔는가?”라는 질문을 던진다는 점을 강조한다. 이를 바탕으로 억양을 단순 클래스가 아니라 화자의 지리·사회적 배경을 반영하는 연속적인 확률 분포로 모델링할 필요성을 제시한다.
프로젝트 “Sprekend Nederland”(네덜란드 얘기하기)은 네덜란드 방송사 NTR이 주도하고, 라드보드 대학교, 유니버시티 컬리지 등 여러 기관이 협업해 진행한다. 스마트폰(iOS·Android) 앱을 통해 세 종류의 데이터를 수집한다. 첫째, 44 kHz, 110 kb/s AAC 형식의 음성 녹음; 둘째, 53개의 메타데이터 질문(거주 이력, 출생지, 학교·직장 위치, 모국어, 방언 사용 여부 등); 셋째, 38개의 태도 질문(다른 참가자의 억양을 듣고 이웃으로 삼고 싶은지 등). 메타데이터는 지도 기반 인터페이스로 위치를 직접 지정하게 하여, 화자의 자가 인식 억양 위치와 실제 거주 이력을 고해상도 좌표 데이터로 확보한다.
참가자 모집은 전통 매체와 소셜 미디어를 통해 이루어졌으며, 초기 홍보 후 하루 평균 녹음 수는 급격히 감소하는 지수적 패턴을 보였다. 현재(논문 작성 시점) 약 5 000명의 등록자가 있으며, 연령은 20‑30대가 다수를 차지하고, 성비는 여성 57 %·남성 43 %이다. 참가자 중 약 절반이 “출신지” 질문에 답했으며, 지도상에 표시된 위치는 네덜란드 인구 밀도와 일치한다. 벨기에 출신자는 거의 없는데, 이는 문화적·언론적 경계가 프로젝트 인식에 영향을 미친 것으로 해석된다.
억양 위치의 정의는 세 단계로 구분된다. L₁은 화자가 평생 한 장소에 머물렀을 경우 해당 좌표를 그대로 사용한다. L₂는 현재 거주지 주변을 중심으로 한 확률 분포(p(x))를 적용해, 이웃과의 상호작용이 억양에 미치는 영향을 반영한다. L₃는 시간에 따라 변하는 위치‑시간 확률 밀도 p(x,t)를 도입해, 화자의 이동 이력 전체를 모델링한다. 실제 구현에서는 가우시안 커널을 이용한 연속 분포, 혹은 이동 구간별 δ‑분포 등 다양한 파라미터화 방식을 선택할 수 있다.
평가 측면에서는 전통적인 정확도·F‑score 외에 위치 기반 오차(예: 실제 출신지와 추정 위치 간 거리), 확률 분포의 KL divergence, 그리고 인간 청취자와의 일치율을 포함한다. 또한 NIST LRE에서 사용되는 로그‑스코어링 방식을 차용해, 시스템이 출력하는 확률값의 신뢰성을 정량화한다.
결론적으로, 본 연구는 억양 인식을 고정된 클래스 분류에서 화자의 지리·사회적 배경을 추정하는 연속적 확률 모델로 확장한다. 모바일 기반 대규모 데이터 수집 인프라와 풍부한 메타데이터를 활용함으로써, 억양과 사회적 인식 사이의 복합적 관계를 정량적으로 탐구할 수 있는 새로운 연구 플랫폼을 제공한다. 향후 연구에서는 딥러닝 기반 시퀀스 모델, 베이지안 추정, 그리고 다중 모달(음성·텍스트·위치) 융합 기법을 적용해 자동 억양 위치 추정의 정확도와 실용성을 높이는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기