계층형 생성 신경망으로 구현하는 종단 대화 시스템
초록
본 논문은 대규모 대화 코퍼스를 활용해 단어를 하나씩 생성하는 생성 모델을 제안한다. 기존의 계층형 재귀 인코더‑디코더(HRED)를 대화에 맞게 확장하고, 양방향 인코더와 사전 학습된 워드 임베딩·질문‑답변 코퍼스를 이용해 성능을 크게 향상시킨다. 실험은 영화 대본 기반 MovieTriples 데이터셋에서 수행했으며, 제안 모델이 n‑gram 및 일반 RNN 기반 언어 모델보다 우수함을 입증한다.
상세 분석
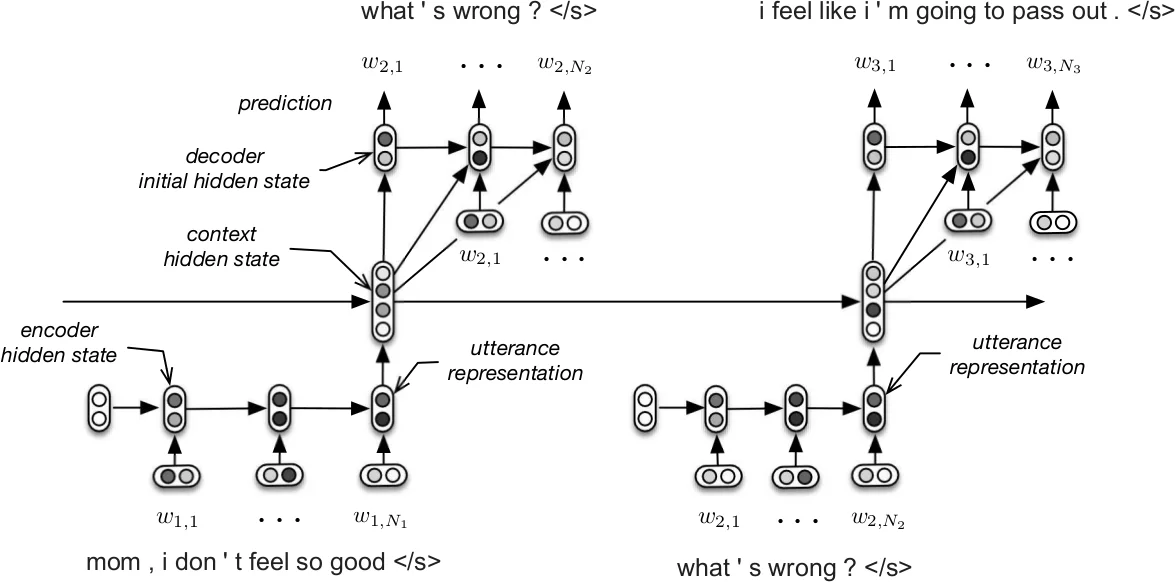
이 논문은 대화 시스템을 “생성적 확률 모델”로 정의하고, 대화 전체를 토큰 시퀀스의 연속으로 모델링한다. 핵심 아이디어는 두 단계의 계층 구조를 도입한 HRED 모델이다. 첫 번째 레벨에서는 각 발화를 단어‑레벨 RNN(주로 GRU)로 인코딩해 고정 길이의 발화 벡터를 만든다. 두 번째 레벨에서는 발화 벡터들을 시간 순서대로 입력받는 컨텍스트 RNN을 두어 대화의 장기적 흐름과 공통 기반(common ground)을 지속적으로 업데이트한다. 컨텍스트 RNN의 최종 은닉 상태는 디코더 RNN의 초기 상태가 되어, 다음 발화를 단어‑레벨에서 순차적으로 생성한다.
모델 개선을 위해 두 가지 주요 전략을 적용한다. 첫째, 발화 인코더를 양방향 RNN으로 교체한 HRED‑Bidirectional을 도입했다. 이는 긴 발화의 앞부분 정보가 마지막 은닉 상태에 충분히 반영되지 않을 위험을 완화하고, 전·후 문맥을 동시에 활용해 더 풍부한 발화 표현을 얻는다. 둘째, 사전 학습된 Word2Vec 임베딩(구글 뉴스 100B 토큰)과 영화 자막에서 추출한 5.5M Q‑A 쌍으로 구성된 SubTle 코퍼스를 이용해 모델 파라미터를 초기화한다. 특히 Q‑A 쌍을 두 턴 대화로 변환해 사전 학습함으로써, 대화 전반에 걸친 일반적인 질문‑응답 패턴과 어휘 정보를 사전에 습득하게 된다.
실험은 MovieTriples 데이터셋(약 200k 삼중 대화)에서 진행했으며, 평가 지표는 퍼플렉시티와 인간 평가를 포함한다. 결과는 (1) 기본 RNN 언어 모델, (2) 5‑그램 백오프 모델, (3) 사전 학습 없이 HRED와 비교했을 때, 사전 학습된 워드 임베딩과 Q‑A 사전 학습을 결합한 HRED‑Bidirectional이 가장 낮은 퍼플렉시티를 기록했다. 인간 평가에서도 제안 모델이 더 자연스럽고 일관된 응답을 생성한다는 점이 확인되었다.
한계점으로는 (a) 생성된 응답이 여전히 다소 일반적이며, 대화 목표나 의도 제어가 어려운 점, (b) 모델이 대규모 파라미터(수백만) 때문에 학습 비용이 높고, (c) 평가가 주관적 퍼플렉시티와 인간 판정에 의존해 실제 상호작용에서의 효용을 완전히 측정하기 어렵다는 점을 언급한다. 향후 연구 방향으로는 강화학습을 통한 목표 기반 보상 설계, 대화 행동(액트) 레이블을 포함한 멀티태스크 학습, 그리고 더 다양한 도메인(예: 고객 지원)으로의 전이 학습을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기