영어 정신 어휘 사전 성장 모델링: 다중층 네트워크의 통찰
초록
이 논문은 영어 단어들을 음운·동의어·연관어 세 층의 멀티플렉스 네트워크로 구성하고, 음운 층을 기반으로 한 성장 모델을 통해 단어 습득 시기의 실험 데이터를 재현한다. 단어 삽입 순서와 거부 확률이 어휘 형성 속도에 미치는 영향을 분석해, 언어 습득이 다중 수준의 구조적 특성에 의해 좌우된다는 가설을 정량적으로 뒷받침한다.
상세 분석
본 연구는 인간 정신 어휘(HML)를 다중층(멀티플렉스) 네트워크로 형식화함으로써 기존의 단일층 네트워크 분석이 놓친 상호작용을 포착한다. 세 층은 (i) 음운 유사성, (ii) 동의어 관계, (iii) 자유 연상 관계이며, 각각 무방향, 비가중 그래프로 구현하였다. 데이터는 WordNet 3.0과 Edinburgh Associative Thesaurus, 그리고 OpenSubtitles 코퍼스를 결합해 4,731개의 일반 사용 단어를 추출했으며, 각 층의 차수 분포, 클러스터링 계수, 평균 경로 길이 등 전형적인 소규모 세계 특성을 보였다. 특히 음운 층은 차수 약 30에서 급격히 절단되는 구조와 높은 동질성(assortativity)을 나타내어, 실제 발음 공간의 제약을 반영한다는 점이 주목된다.
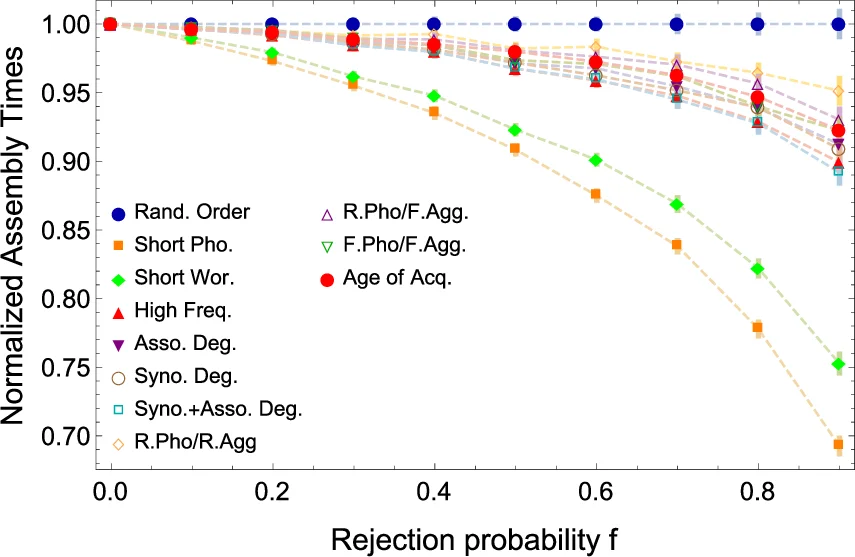
성장 모델은 ‘로컬리스트’ 접근을 차용해, 매 시점 새로운 단어를 후보 리스트에서 선택하고, 기존 네트워크와 음운 층에서 최소 하나의 연결이 형성되면 받아들이고, 그렇지 않으면 확률 f 에 따라 거부한다. 후보 선택 순서는 (1) 무작위, (2) 음운 길이 기준, (3) 철자 길이 기준, (4) 단어 빈도, (5) 복합적인 멀티플렉스 중심성(예: 다중층 차수, 페이지랭크) 등으로 다양화하였다. 모델의 유일한 자유 파라미터는 거부 확률 f 이며, 전체 어휘가 완성될 때까지의 평균 조립 시간 T 을 측정한다.
실험 결과는 단어 삽입 순서가 T 에 큰 영향을 미친다는 것을 보여준다. 짧은 음운·철자를 우선하는 전략은 조립 시간을 크게 단축시켰으며, 이는 인간이 초기 언어 습득 단계에서 발음하기 쉬운 짧은 형태를 먼저 학습한다는 심리언어학적 증거와 일치한다. 반면 빈도 기반 순서는 중간 정도의 효율을 보였고, 무작위 순서는 가장 오래 걸렸다. 또한, 멀티플렉스 중심성을 활용한 순서는 음운·의미 층 모두에서 높은 연결성을 가진 단어를 먼저 삽입함으로써, 전체 네트워크의 응집성을 빠르게 증가시켜 T 를 최소화했다.
연령별 어휘 습득 데이터(연구
댓글 및 학술 토론
Loading comments...
의견 남기기