데이터 검정 교육을 위한 세 가지 접근법 완전 정리
초록
본 튜토리얼은 행동·사회·생물의학 분야에서 여전히 널리 사용되는 영가설 유의성 검정(NHST)의 교육적 대안을 제시한다. 피셔의 유의성 검정, 네이만‑피어슨의 검정‑수용 이론, 그리고 이 두 이론을 혼합한 현재의 NHST를 순차적으로 설명하고, NHST를 고수하는 연구자를 위한 두 가지 실용적 개선 방안을 제시한다.
상세 분석
이 논문은 데이터 검정 교육의 근본적인 전환점을 ‘가르침’에 두고 있다. 먼저 피셔(Fisher)의 접근을 ‘유의성 검정’이라 정의하고, p값을 관찰된 데이터가 영가설 하에서 얼마나 드물게 나타나는지를 나타내는 지표로 해석한다. 여기서 강조되는 핵심은 ‘귀무가설을 기각할지 말지’가 아니라 ‘관측된 결과가 우연히 발생했을 가능성을 정량화’하는 것이다. 피셔는 사후적 판단을 중시하며, 연구자가 사전에 대립가설을 명시하지 않아도 된다.
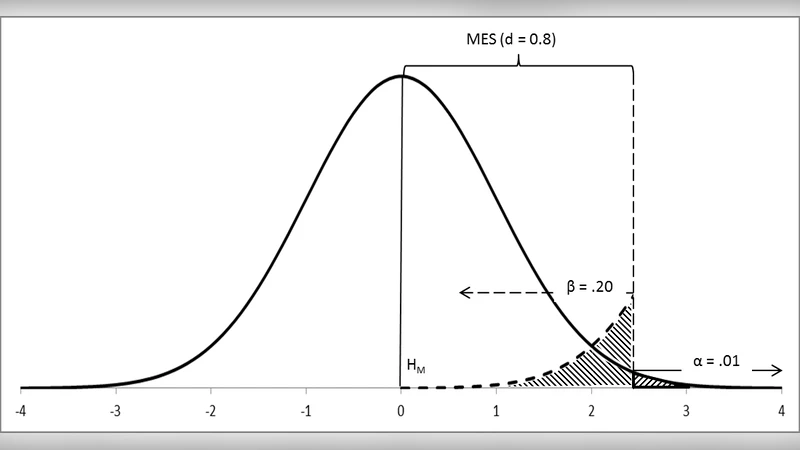
다음으로 네이만‑피어슨(Neyman‑Pearson)의 ‘검정‑수용’ 프레임을 소개한다. 이 접근은 사전적 오류율(α, β)을 설정하고, 검정력(1‑β)을 최적화하는 절차적 규칙을 제공한다. 여기서는 영가설(H0)과 대립가설(H1)을 명확히 구분하고, ‘수용’ 혹은 ‘기각’이라는 이산적 결정을 내린다. 이론적 토대는 ‘결정 이론’에 기반해, 연구 설계 단계에서 표본 크기와 효과 크기를 미리 고려하도록 요구한다.
논문은 이 두 이론이 실제 연구에서 혼합되어 사용되는 현상을 ‘NHST(Null‑Hypothesis Significance Testing)’라 명명하고, 그 모순을 비판한다. NHST는 피셔의 p값 해석과 네이만‑피어슨의 오류율 규칙을 동시에 적용하려다 보니, 연구자가 p<.05를 ‘통계적 유의성’으로 오해하고, 동시에 사전 검정력 분석을 무시하는 혼란을 초래한다. 저자는 이러한 혼합이 교육 현장에서 가장 큰 혼동을 일으킨다고 지적한다.
교육적 차원에서 저자는 세 단계의 교수법을 제안한다. 1) 피셔와 네이만‑피어슨을 각각 독립된 이론으로 명확히 구분해 가르친다. 2) 각 이론의 적용 상황과 한계를 사례 중심으로 토론한다. 3) NHST를 그대로 사용해야 하는 경우, 두 이론의 장점을 보완하는 ‘두 단계 검정(Pre‑test → Post‑test)’ 혹은 ‘베이즈적 보완(Bayesian augmentation)’을 도입한다. 특히, 사전 검정력 분석과 사후 p값 보고를 동시에 수행하도록 권고한다.
마지막으로, NHST를 완전히 폐기하기 어려운 현실을 인정하고, 두 가지 실용적 개선책을 제시한다. 첫째, p값과 함께 효과 크기와 신뢰구간을 보고하도록 강제한다. 둘째, 연구 설계 단계에서 α와 β를 명시하고, 검정력 분석을 필수 절차로 만든다. 이러한 조치는 NHST의 모호성을 줄이고, 결과 해석의 투명성을 높이는 데 기여한다.
전반적으로 논문은 ‘교육이 변화를 이끈다’는 전제 하에, 데이터 검정 이론을 체계적으로 구분하고, 현행 NHST의 문제점을 구체적인 교육 전략과 실천적 가이드라인으로 연결한다. 이는 학부·대학원 교육자뿐 아니라 연구자들에게도 실질적인 인식 전환을 촉구한다.
댓글 및 학술 토론
Loading comments...
의견 남기기