일반 추천 시스템을 위한 요구공학
초록
본 논문은 일반화된 추천 시스템 프레임워크 구축을 위한 요구공학 관점을 제시한다. 체계적 문헌조사를 통해 사용자와 아이템 데이터 유형을 분류하고, 이를 기반으로 통합 사용자·아이템 모델을 설계한다. 또한 알고리즘 별 파라미터 고려사항과 빅데이터·IoT가 요구공학에 미치는 영향을 논의한다.
상세 분석
본 연구는 추천 시스템 개발 단계에서 가장 핵심적인 ‘데이터 요구사항 정의’를 자동화하려는 시도로, 기존의 수작업 기반 요구공학이 갖는 비용·오류 문제를 해결하고자 한다. 이를 위해 저자들은 2010년부터 2023년까지 발표된 212편의 논문을 대상으로 PRISMA 기반 체계적 리뷰를 수행했으며, 데이터 유형을 크게 ‘사용자 프로필 데이터’, ‘사용자 행동 데이터’, ‘콘텐츠 메타데이터’, ‘컨텍스트 데이터’ 네 축으로 정리하였다. 특히 사용자 프로필 데이터는 인구통계학적 속성, 심리적 특성, 사회적 관계망 정보로 세분화되었고, 행동 데이터는 명시적 피드백(평점, 좋아요)과 암시적 피드백(클릭, 체류시간, 구매 이력)으로 구분하였다. 아이템 측면에서는 정형 메타데이터(카테고리, 가격, 출시일)와 비정형 메타데이터(텍스트 설명, 이미지, 오디오)로 나뉘며, 각각을 벡터화하거나 임베딩하는 방법론이 제시된다.
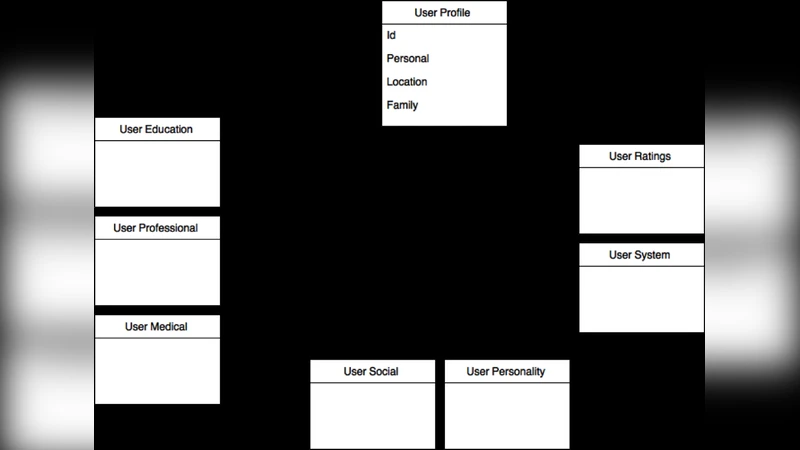
제안된 통합 사용자·아이템 모델은 UML 기반 클래스 다이어그램으로 시각화되었으며, 핵심 클래스는 ‘User’, ‘Item’, ‘Interaction’, ‘Context’ 로 구성된다. 각 클래스는 속성(attribute)과 연관 관계(association)를 명시함으로써 요구공학 단계에서 데이터 스키마를 자동 생성할 수 있게 설계되었다. 예를 들어, ‘Interaction’ 클래스는 ‘rating’, ‘timestamp’, ‘deviceType’ 등을 포함하고, ‘Context’ 클래스는 ‘location’, ‘weather’, ‘networkCondition’ 등을 캡처한다. 이러한 모델링은 협업 필터링, 콘텐츠 기반 필터링, 하이브리드 필터링 등 다양한 알고리즘에 공통적으로 적용 가능하도록 설계되었다.
알고리즘 별 파라미터 고려사항에서는 KNN 기반 협업 필터링의 ‘k값’, 행렬 분해 기법의 ‘잠재 요인 차원 수’, 딥러닝 기반 모델의 ‘학습률’ 및 ‘배치 크기’ 등을 요구사항 문서에 명시하도록 권고한다. 특히 파라미터 튜닝에 필요한 메트릭(정밀도, 재현율, NDCG 등)과 실험 설계(교차 검증, 하이퍼파라미터 탐색 범위)도 요구공학 단계에서 정의함으로써 개발 주기를 단축시킬 수 있음을 강조한다.
빅데이터와 IoT의 영향에 대해서는 데이터 볼륨·속도·다양성(3V) 증가가 요구공학에 새로운 도전을 제시한다는 점을 지적한다. 빅데이터 환경에서는 분산 저장·처리 프레임워크(Hadoop, Spark)와 스트리밍 플랫폼(Kafka, Flink)을 고려한 데이터 파이프라인 설계가 필요하며, IoT 디바이스에서 발생하는 실시간 컨텍스트 데이터(센서값, 위치 정보)를 모델에 통합하기 위해 시계열 데이터 스키마와 이벤트 기반 트리거 메커니즘을 요구사항에 포함시켜야 한다.
한계점으로는 체계적 리뷰가 주로 학술 논문에 국한되어 산업 현장의 실무 데이터 요구와 차이가 있을 수 있다는 점, 제안된 모델이 모든 도메인에 완전히 적용 가능하다는 보장은 없다는 점을 인정한다. 향후 연구에서는 도메인 별 맞춤형 확장 모델링과 자동 요구사항 추출을 위한 자연어 처리(NLP) 기반 도구 개발이 필요하다고 제언한다.