반복 모델 개발을 위한 구조화된 스프레드시트 모델링 및 구현 방법론
초록
본 논문은 동일한 구조를 가진 여러 개의 변수와 수식이 존재하는 스프레드시트에서, 공통된 패턴을 추출해 하나의 일반화된 수식으로 통합하는 개념적 모델링 접근법을 제시한다. 이를 기반으로 구조화된 스프레드시트 모델링 및 구현 방법론(SSMI)을 제안하고, 엄격한 규칙을 통해 반복적인 계산을 효율적으로 설계·구현하는 절차를 설명한다.
상세 분석
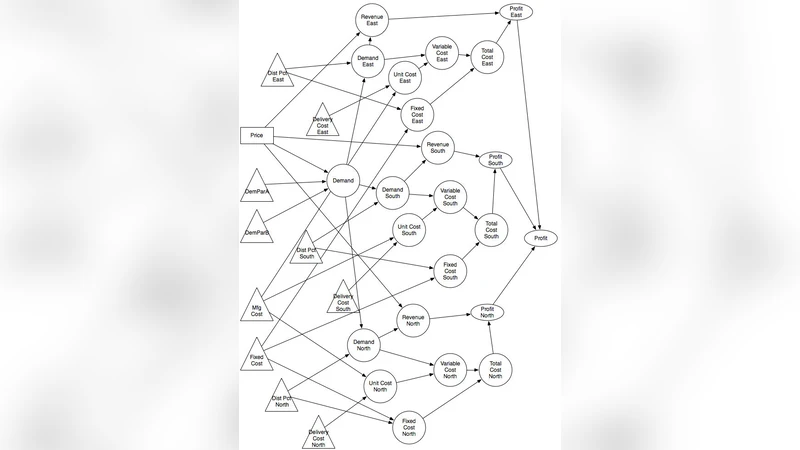
이 연구는 스프레드시트 개발 시 흔히 마주치는 “반복 구조” 문제를 체계적으로 해결하고자 한다. 저자들은 먼저 동일한 연산 로직이 여러 엔터티(예: 지역, 제품, 기간 등)에 대해 반복되는 현상을 관찰하고, 이를 “패턴”이라고 정의한다. 이러한 패턴을 식별하기 위해서는 변수명과 수식의 구성 요소를 분해하고, 공통된 부분과 차별화된 부분을 명확히 구분해야 한다. 논문은 이를 위해 ‘엔터티 식별 단계’, ‘공통 변수 추출 단계’, ‘일반화 수식 정의 단계’라는 3단계 절차를 제시한다.
첫 번째 단계에서는 스프레드시트 전체를 메타데이터 형태로 매핑하여, 각 셀에 연관된 엔터티와 속성을 태깅한다. 여기서 중요한 점은 엔터티 간의 계층 구조를 명시함으로써, 하위 엔터티가 상위 엔터티의 속성을 자동으로 상속받게 하는 것이다. 두 번째 단계에서는 동일한 연산 패턴을 가진 셀들을 그룹화하고, 변수명에서 엔터티 식별자를 제거한 ‘핵심 변수’를 도출한다. 예를 들어, “Revenue_South”와 “Revenue_East”는 “Revenue”라는 핵심 변수를 공유한다.
세 번째 단계에서는 핵심 변수를 기반으로 일반화된 수식을 작성한다. 이때 수식은 ‘엔터티 인덱스’를 파라미터로 받아, 해당 인덱스에 대응하는 데이터(가격, 수량 등)를 자동으로 참조하도록 설계한다. 이를 구현하기 위해 저자는 ‘구조화된 스프레드시트 모델링 및 구현 방법론(SSMI)’을 제안한다. SSMI는 (1) 데이터 입력 시트, (2) 계산 로직 시트, (3) 출력 시트로 구성된 3계층 아키텍처를 채택한다. 각 계층은 명확한 인터페이스를 통해 연결되며, 데이터 입력 시트는 엔터티별 원시 데이터를 표 형태로 수집한다. 계산 로직 시트에서는 일반화된 수식을 배열 함수(예: INDEX, MATCH, OFFSET)와 함께 사용해, 엔터티 인덱스에 따라 동적으로 결과를 산출한다. 마지막 출력 시트는 사용자에게 친숙한 형태로 결과를 표시하고, 필요 시 차트와 대시보드로 시각화한다.
또한 논문은 구현 규칙을 7가지로 정리한다. 첫째, 변수명은 ‘핵심명_엔터티명’ 형태로 일관되게 명명한다. 둘째, 모든 수식은 가능한 한 단일 셀에 집약하지 말고, 배열 수식이나 테이블 구조를 활용해 복제성을 확보한다. 셋째, 입력 데이터는 절대 참조가 아닌 테이블 이름을 사용해 동적 범위를 지정한다. 넷째, 계산 로직은 반드시 ‘엔터티 인덱스’를 첫 번째 인수로 받는 함수 형태로 작성한다. 다섯째, 중간 결과는 별도 시트에 저장해 디버깅과 검증을 용이하게 한다. 여섯째, 시트 간 의존성은 순환되지 않도록 DAG(Directed Acyclic Graph) 형태로 설계한다. 일곱째, 문서화는 메타데이터 시트를 활용해 변수 정의, 단위, 설명을 자동으로 생성한다.
이러한 규칙과 절차를 따르면, 스프레드시트는 동일한 로직을 여러 번 복사·붙여넣기 하는 비효율적인 작업에서 벗어나, 구조화된 모델로 재사용성과 유지보수성을 크게 향상시킨다. 특히 대규모 재무 모델, 영업 예측, 공급망 시뮬레이션 등에서 엔터티 수가 수십에서 수백에 달할 때, 이 방법론은 오류 발생률을 현저히 낮추고, 모델 변경 시 일관된 업데이트를 가능하게 한다.
마지막으로 저자는 실제 사례 연구를 통해 SSMI 적용 전후의 개발 시간, 오류 수, 유지보수 비용을 비교한다. 결과는 평균 개발 시간이 35% 감소하고, 오류 발생률이 60% 이상 감소했으며, 모델 수정 시 평균 4시간이 소요되던 작업이 1시간 이하로 단축되는 등 실질적인 효익을 입증한다. 이러한 정량적 결과는 제안된 방법론이 이론적 가치를 넘어 실무 적용 가능성을 충분히 뒷받침한다.
댓글 및 학술 토론
Loading comments...
의견 남기기