중국어 단어 분할을 위한 양방향 LSTM 신경망
초록
본 논문은 손수 만든 특징 없이 문자 임베딩만으로 중국어 단어 분할을 수행하는 양방향 LSTM(BLSTM) 모델을 제안한다. 문자마다 B‑M‑E‑S 태그를 부여해 순차 태깅 문제로 전환하고, 단일 BLSTM 층부터 3층까지 쌓은 심층 구조를 실험한다. 실험 결과, PKU, MSRA, AS, HK 등 SIGHAN 2005 베치마크 데이터셋에서 기존 최첨단 방법들을 능가하거나 동등한 수준의 F1 점수를 얻으며, 특히 임베딩 차원 200과 23층 BLSTM이 최적임을 확인한다. 모델은 GPU에서 1617시간 내에 학습되며, 사전 지식이나 외부 데이터 없이도 높은 일반화 성능을 보인다.
상세 분석
이 연구는 중국어 단어 분할(CWS)을 전통적인 특징 기반 방법에서 완전한 신경망 기반 방법으로 전환하는 데 초점을 맞춘다. 기존의 CRF나 HMM 기반 시스템은 풍부한 손수 만든 특징(문맥 윈도우, 사전 정보, 문자 형태 등)을 필요로 했지만, BLSTM은 이러한 전처리 없이도 문맥 정보를 양방향으로 자동 학습한다는 점이 핵심이다.
먼저 저자는 CWS를 B(시작), M(중간), E(끝), S(단일 문자) 네 가지 태그로 변환한다. 각 문자에 대해 고유 ID를 부여하고, 이를 d 차원의 임베딩 벡터로 매핑한다. 임베딩은 무작위 초기화 후 학습 과정에서 동시에 최적화되며, 이는 문자 수준에서 의미론적·형태론적 정보를 압축한다.
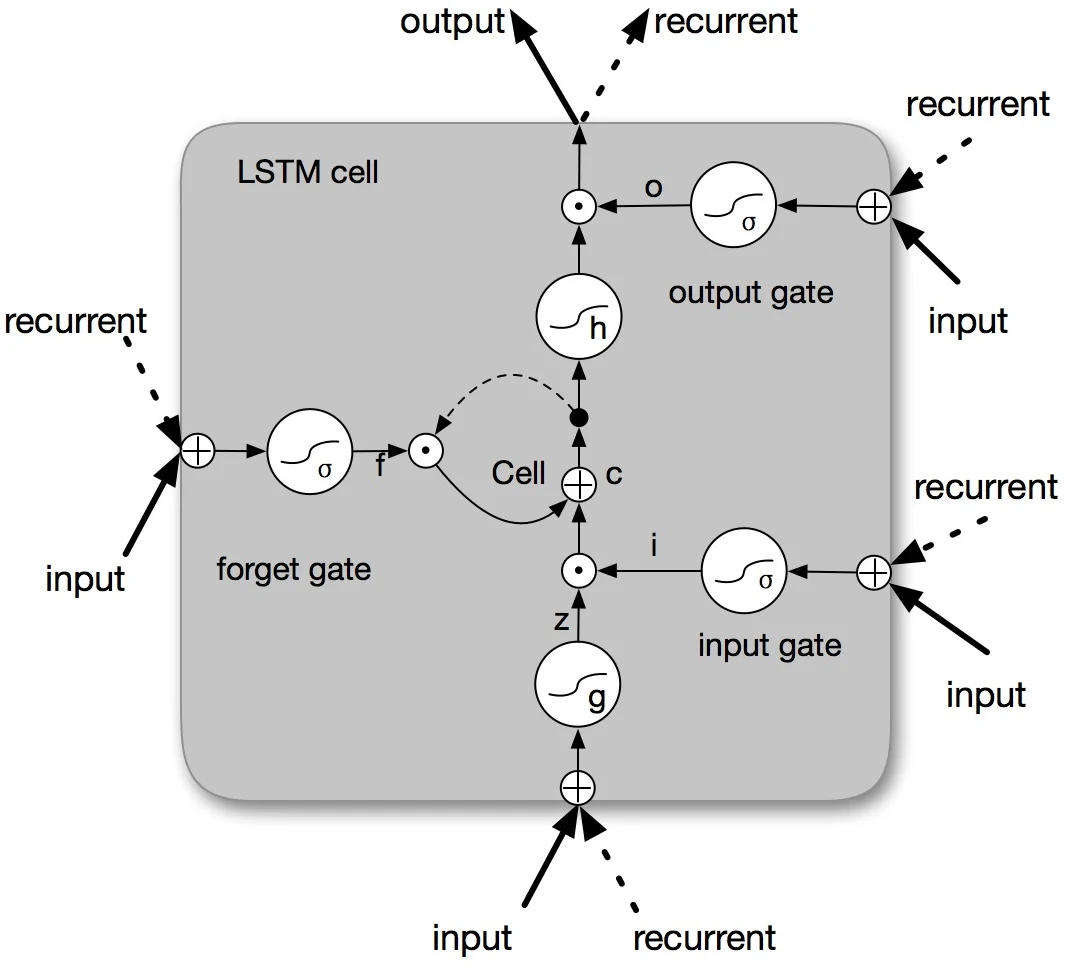
BLSTM 구조는 전방 LSTM과 후방 LSTM을 병렬로 배치하고, 두 출력 벡터를 연결(concatenation)해 최종 은닉 표현을 만든다. 이때 출력 차원은 2d가 되므로, 심층 모델을 구성할 경우 차원 폭발을 방지하기 위해 선형 변환 행렬 W_tran을 도입해 2d → d 로 압축한다. 이렇게 하면 층을 쌓아도 파라미터 수가 급격히 증가하지 않는다.
학습 단계에서는 소프트맥스 레이어를 통해 각 문자에 대한 네 개 태그의 확률을 계산하고, 교차 엔트로피 손실을 최소화한다. 과적합 방지를 위해 드롭아웃을 적용했으며, 배치 크기와 학습률은 GPU 메모리 제한에 맞춰 조정하였다.
실험에서는 임베딩 차원을 100, 128, 200, 300으로 변형해 성능을 비교했으며, 차원 200이 가장 안정적이고 높은 F1을 기록했다. BLSTM 층 수를 13개로 늘려 보았을 때, 23층이 약간의 성능 향상을 보였지만 3층을 넘어가면 학습 비용이 급증하고 수렴이 어려워 실용성이 떨어진다.
베치마크 데이터셋(PKU, MSRA, AS, HK)에서 제안 모델은 기존 최고 성능(LSTM*, Bi‑RNN 등)과 비교해 평균 0.3~0.5%p 정도 향상된 F1을 달성했다. 특히, 기존 연구가 외부 사전이나 대규모 비지도 학습을 활용한 반면, 본 모델은 전적으로 학습 데이터만을 사용했다는 점에서 데이터 효율성이 강조된다.
한계점으로는 모델이 아직도 대규모 데이터와 GPU 자원에 의존한다는 점, 그리고 문자 수준 임베딩만 사용해 어휘 수준 정보를 완전히 포착하지 못할 가능성이 있다. 또한, 실험이 SIGHAN 2005 데이터에 국한돼 있어 최신 웹 텍스트나 도메인 특화 데이터에 대한 일반화 검증이 부족하다. 향후 연구에서는 문자와 단어 수준 임베딩을 결합하거나, CRF 레이어를 추가해 전역 태그 제약을 강화하는 방안을 고려할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기