멀티모달 전이 딥러닝으로 음성‑영상 인식 혁신
초록
본 논문은 음성 전용 딥넷에서 학습된 지식을 영상(입술 읽기) 네트워크에 전이시키는 프레임워크를 제안한다. 중간 층의 추상 표현을 유사성 보존 임베딩으로 매핑한 뒤, 전이된 특징을 이용해 영상 네트워크를 부분적으로 미세조정(TDLFT)한다. AV‑Letters와 Stanford 두 데이터셋에서 전이 학습이 기존 영상 단일모달 모델보다 높은 정확도를 달성함을 보였다.
상세 분석
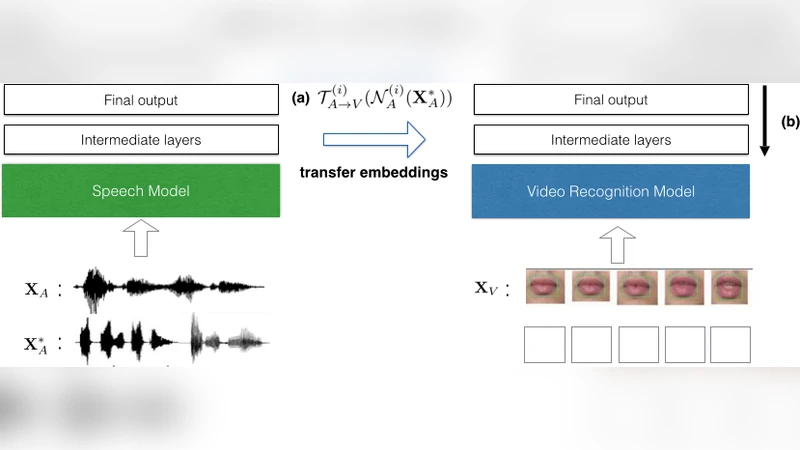
이 연구는 멀티모달 데이터가 불균형하게 존재할 때, 풍부한 한 모달리티(음성)의 라벨 정보를 활용해 부족한 다른 모달리티(입술 영상)의 성능을 향상시키는 전이 딥러닝(TDL) 방식을 설계하였다. 핵심 아이디어는 두 개별 딥 네트워크(N_A, N_V)를 각각 음성·영상에 대해 사전 학습한 뒤, 각 네트워크의 i번째 중간 층 출력 H_A^{(i)}, H_V^{(i)} 사이에 아날로지 보존 임베딩 T_{A→V}^{(i)}를 학습하는 것이다. 임베딩 방법으로는 (1) 비선형 커널을 이용한 다변량 서포트 벡터 회귀(SVR), (2) K‑최근접 이웃 기반 비모수 매핑(KNN), (3) 정규화된 정준 상관 분석(NCCA) 세 가지를 실험하였다. 이후 새로운 음성 샘플 X*A를 N_A에 통과시켜 H_A^{(i)}를 얻고, 이를 T{A→V}^{(i)}에 입력해 추정된 영상 특징 H_V^{(i)}를 생성한다. 이 특징을 영상 네트워크 N_V의 i번째 층 입력으로 삽입하고, i부터 최상위 층(l)까지 역전파를 수행해 가중치를 미세조정하는 알고리즘을 TDLFT(i)라 명명하였다. i값을 크게 잡을수록 전이된 특징이 고수준 의미에 가까워 신뢰도가 높지만, 미세조정 가능한 층이 적어 전체 네트워크에 미치는 영향이 제한된다. 반대로 i를 작게 잡으면 저수준 특징까지 전이되지만, 서로 다른 모달리티 간 입력 공간 차이로 인해 매핑 정확도가 떨어져 성능 저하 위험이 있다. 실험에서는 i=3(중간‑고수준 층)에서 가장 안정적인 향상을 보였으며, KNN 기반 임베딩이 전반적으로 가장 높은 정확도를 제공하였다. 또한, 완벽한 전이(Oracle) 상황을 가정한 상한선과 비교했을 때 현재 제안된 방법이 여전히 여유가 있음을 확인하였다. 한계점으로는 임베딩 학습 단계가 별도 비용을 요구하고, 저수준 전이 시 잡음이 섞인 특징이 네트워크에 전달돼 성능이 오히려 악화될 수 있다는 점을 들 수 있다. 향후 연구에서는 전이된 특징을 이용해 역방향 생성 모델을 구축해 음성으로부터 입술 영상을 합성하거나, 보다 정교한 공동 잠재 공간 학습을 통해 전이 효율을 높이는 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기