스파이킹 신경망의 정보 이론 기반 학습 방법
초록
본 논문은 확률적 스파이킹 뉴런 모델을 이용해 스파이킹 신경망을 정보 이론적 비용 함수로 학습시키는 방법을 제안한다. 부정 로그우도(서프라이얼), 엔트로피, 강화학습용 필터링 서프라이얼을 최소화하는 규칙을 각각 감독, 비감독, 강화 학습 과제에 적용하고, 패턴 검출, 자동 연관 기억, 가상 에이전트 제어 실험을 통해 유효성을 검증한다.
상세 분석
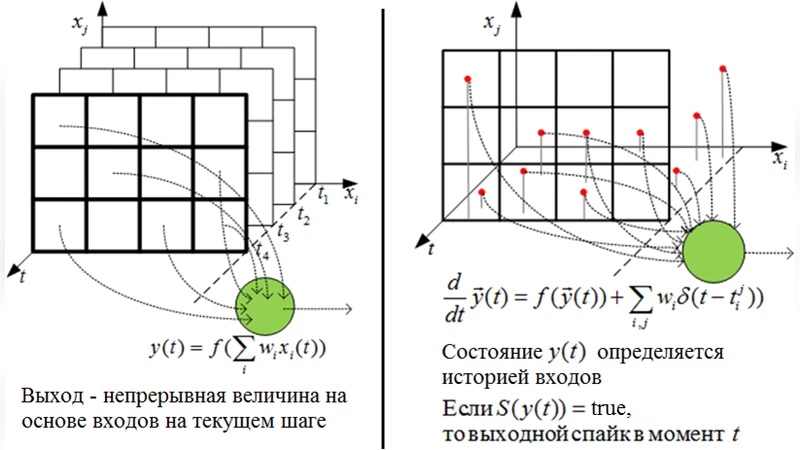
스파이킹 신경망(SNN)은 뉴런 간 통신을 이산적인 스파이크(‘예/아니오’ 이벤트)로 구현한다는 점에서 전통적인 연속값 기반 인공신경망과 근본적으로 다르다. 이산성 때문에 미분 가능한 손실 함수를 정의하기 어려워, 기존의 역전파(Back‑Propagation)와 같은 경사 하강법을 직접 적용하기 힘들다. 저자는 이러한 난관을 극복하기 위해 확률적 스파이킹 뉴런 모델을 채택한다. 여기서 뉴런의 스파이크 발생 확률은 파라미터(가중치, 바이어스 등)의 연속적인 함수로 표현되며, 이는 확률적 그래픽 모델에서 흔히 쓰이는 로짓 혹은 시그모이드 형태와 유사하다. 따라서 확률분포 자체에 대해 미분이 가능해져, 정보 이론적 비용 함수를 직접 최소화하는 학습 규칙을 도출할 수 있다.
논문은 세 가지 주요 학습 목표를 설정한다. 첫째, 감독 학습에서는 목표 스파이크 패턴을 주어진 입력 시퀀스에 매핑하기 위해 ‘서프라이얼(surprisal)’, 즉 부정 로그우도 −log p(y|x)를 최소화한다. 이는 최대우도 추정(Maximum Likelihood Estimation)과 동일한 목표이며, 파라미터 업데이트는 로그우도의 그라디언트를 이용해 간단히 구현된다. 둘째, 비감독 학습에서는 뉴런의 출력 분포가 가능한 한 확정적이면서도 안정적이도록 엔트로피 H(p) = −∑p log p를 최소화한다. 엔트로피 감소는 스파이크 타이밍의 변동성을 줄여, 네트워크가 자체적인 내부 패턴을 형성하고 유지하도록 유도한다. 셋째, 강화 학습에서는 에이전트의 행동 선택이 환경 보상에 따라 조정되도록 ‘필터링 서프라이얼(filtered surprisal)’을 사용한다. 여기서 필터링은 시간적 윈도우 혹은 누적 보상에 대한 지수적 감쇠를 적용해, 최근 보상에 더 큰 가중치를 부여한다. 이렇게 정의된 비용은 정책 그라디언트와 유사한 형태를 띠며, 스파이킹 뉴런의 파라미터가 보상 신호에 따라 직접 조정된다.
저자는 새로운 스파이킹 뉴런 모델을 제안한다. 기존 모델들은 포아송 혹은 이항 스파이크 발생 과정을 가정했지만, 제안 모델은 입력 히스토리와 내부 상태(예: 적응형 역치, 멤브레인 전위)를 모두 고려한 확률적 전이 함수를 포함한다. 이 함수는 시간에 따라 변하는 가중치와 역치를 통해 복잡한 시공간 패턴을 인코딩할 수 있다. 또한, 뉴런 내부의 ‘필터링 메커니즘’은 과거 스파이크의 잔여 효과를 누적해, 장기 의존성을 학습하도록 설계되었다.
실험에서는 (1) 특정 시공간 패턴을 검출하는 감독 학습, (2) 자동 연관 기억(auto‑associative memory)에서 패턴 저장·재생을 위한 비감독 학습, (3) 감독·비감독 학습을 병행해 학습 속도를 가속화한 하이브리드 학습, (4) 변화하는 환경에서 가상 로봇 에이전트를 제어하는 강화 학습을 수행한다. 결과는 모두 제안된 비용 함수 기반 학습 규칙이 기존의 스파이킹 신경망 학습 방법보다 빠른 수렴과 높은 정확도를 보임을 입증한다. 특히, 엔트로피 최소화는 기억 네트워크의 잡음 저항성을 크게 향상시켰으며, 필터링 서프라이얼을 이용한 강화 학습은 환경 변화에 대한 적응성을 빠르게 획득했다. 전체적으로, 확률적 스파이킹 뉴런과 정보 이론적 비용 함수의 결합은 SNN을 실용적인 학습 프레임워크로 전환시키는 중요한 전환점으로 평가될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기