시작점이 안 좋을 때 학습 가속화 전략
본 논문은 초기 파라미터가 최적이 아닌, 즉 “가난한” 시작점에서 머신러닝 모델을 학습할 때 온라인 확률적 경사하강법(Robbins‑Monro)보다 Nesterov 가속과 모멘텀 같은 고차 방법이 초기 몇 번의 반복에서 더 빠른 수렴을 제공한다는 점을 이론적·실험적으로 보여준다. 특히 미니배치 크기를 크게 하면 잡음이 감소해 고차 방법의 유효 기간을 연장할 수 있다.
저자: Mark Tygert
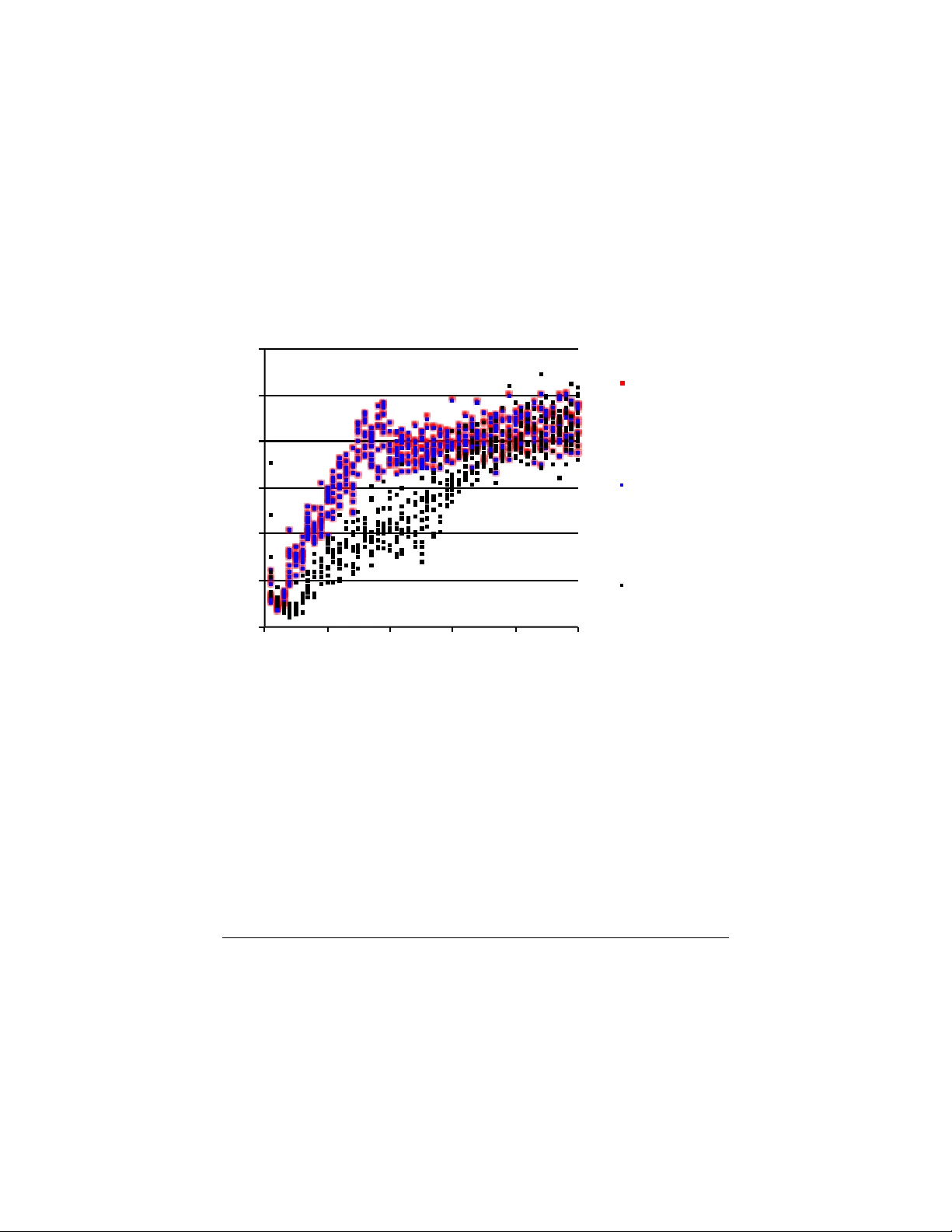
본 논문은 머신러닝 최적화 과정에서 초기 파라미터가 “가난한” 경우, 즉 기대 손실 e(θ)가 샘플 손실의 변동 d(θ,X)보다 현저히 큰 상황을 다룬다. 전통적인 Robbins‑Monro(온라인 확률적 경사하강법, SGD)는 초기점이 충분히 좋은 경우 최적의 수렴 속도(1/√t)를 보장하지만, 초기점이 무작위이거나 크게 비효율적인 경우에는 고차 가속 방법이 초기 수렴을 크게 개선할 수 있다.
1. **문제 정의 및 수학적 배경**
- 손실 함수 c(θ,X)와 기대 손실 e(θ)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기