대규모 생명과학 온톨로지 데이터셋을 위한 MapReduce 기반 효율적 쿼리 처리
초록
본 논문은 풍부한 생물학적 온톨로지를 가진 대규모 RDF 데이터웨어하우스에 대해, 쿼리 재작성으로 생성되는 복잡한 UCQ를 MapReduce 환경에서 효율적으로 실행하기 위한 NTGA 기반 RAPID+ 시스템을 제안한다. 트리플 그룹화를 활용해 조인 단계와 중간 데이터 양을 크게 감소시켜, 실제 UniProt·Bio2RDF·Chem2Bio2RDF 데이터셋에서 기존 방법 대비 현저한 성능 향상을 입증한다.
상세 분석
생명과학 분야의 데이터는 수십 테라바이트 규모로 급증하고, UniProt, Bio2RDF, Chem2Bio2RDF와 같은 온톨로지 기반 통합 저장소가 등장하면서 복합적인 추론 요구가 필수적이다. 전통적인 전방 전파(forward chaining) 방식은 전체 트리플을 미리 물리화해야 하므로 업데이트 비용이 비싸고, 대규모 데이터에 적용하기 어렵다. 대신, 쿼리 재작성(query rewriting) 기법은 원본 쿼리를 온톨로지 규칙에 따라 확장해 Union of Conjunctive Queries(UCQ) 형태로 변환한다. 그러나 생물학적 온톨로지는 깊고 넓은 서브클래스 계층(25레벨, 1.3백만 클래스)을 갖기 때문에, 재작성된 UCQ는 수백 개의 UNION과 수천 개의 JOIN을 포함한다. 기존 관계형 최적화 기법은 이러한 고폭도(높은 UNION 수)와 다중 조인에 비효율적이며, 특히 MapReduce와 같은 클라우드 플랫폼에서는 각 조인마다 Map/Reduce 사이클이 필요해 디스크·네트워크 I/O 비용이 급증한다.
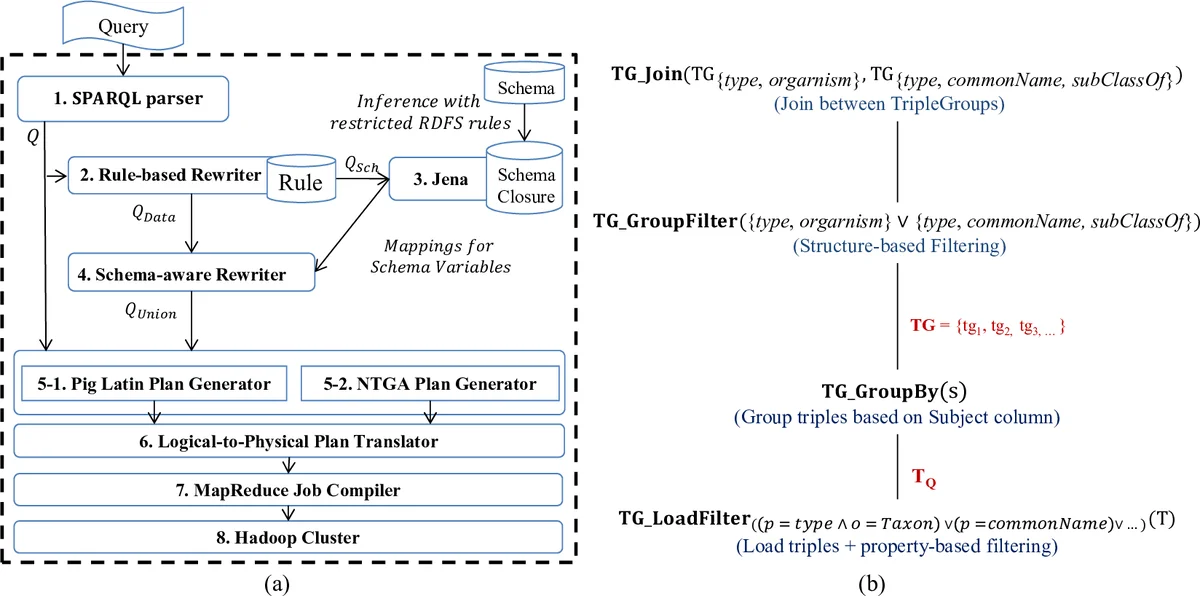
논문은 이러한 문제를 해결하기 위해 Nested Triple Group Data Model and Algebra(NTGA)를 도입한다. NTGA는 동일 주체(subject)를 공유하는 트리플들을 “트리플 그룹(triple‑group)”이라는 단위로 묶어 첫 번째 클래스 객체로 취급한다. TG GroupBy 연산은 주체 컬럼을 기준으로 GROUP BY를 수행해 모든 트리플 그룹을 한 번에 생성하고, TG GroupFilter는 쿼리의 스타 패턴(star‑pattern)과 일치하는 그룹만 남긴다. 이렇게 하면 여러 스타 패턴을 동시에 매칭할 수 있어, 기존 관계형 방식이 스타 패턴당 별도 조인 작업을 수행하던 것을 한 번의 MapReduce 작업으로 대체한다. 이후 TG Join 연산을 통해 필요한 스타 패턴 간의 조인을 수행하는데, 전체 작업 수는 2 n − 1이 아닌 n + 1(첫 번째 그룹화·필터링 작업 + 각 스타 패턴당 한 번씩)으로 크게 감소한다.
RAPID+는 Apache Pig 위에 구현된 시스템으로, Jena ARQ 혹은 확장된 Pig Latin 인터페이스를 통해 SPARQL 쿼리를 파싱하고, Rule‑based Query Rewriter가 온톨로지 규칙에 따라 UCQ를 생성한다. 논문에서는 이 과정에 세 개의 새로운 모듈(규칙 기반 재작성, 스키마‑인식 재작성, NTGA 플랜 생성기)을 추가해 기존 Pig 플랜과 NTGA 플랜을 동시에 생성한다. 논리‑물리 플랜 변환 단계에서는 NTGA 연산을 MapReduce 작업으로 매핑하고, Job Compiler가 최적화된 MR 워크플로우를 자동 생성한다. 실험에서는 UniProt(수 TB 규모, 25레벨 서브클래스), Bio2RDF, Chem2Bio2RDF 데이터에 대해 10~30배 정도의 실행 시간 단축을 보였으며, 특히 UNION이 200개 이상인 복잡한 쿼리에서 기존 관계형 접근법이 타임아웃되는 반면 RAPID+는 정상적으로 결과를 반환했다. 또한 중간 데이터 양이 평균 70% 감소해 네트워크 부하와 디스크 I/O를 크게 완화하였다. 이러한 결과는 NTGA 기반 트리플 그룹화가 대규모 온톨로지 쿼리의 병렬 처리에 적합함을 실증한다.
핵심 기여는 (1) 고폭도 UCQ를 효율적으로 처리하기 위한 NTGA 연산 집합 정의, (2) 이를 MapReduce 환경에 매핑한 RAPID+ 시스템 구현, (3) 실제 생명과학 대규모 데이터셋을 이용한 정량적 성능 검증이다. 제한점으로는 트리플 그룹화 과정에서 메모리 사용량이 증가할 수 있으며, 매우 희소한 속성 조합에 대해서는 그룹 필터링 비용이 오히려 늘어날 가능성이 있다. 향후 연구에서는 동적 그룹 크기 조정, 비용 기반 조인 순서 최적화, 그리고 Spark와 같은 인메모리 분산 프레임워크에 대한 적용을 검토하고 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기