통계 추론의 함정과 표본 이질성 탐지
초록
본 논문은 내부 프로토콜에 따라 생성된 의사난수 실험 데이터를 대상으로, 10만 건 이상의 대규모 표본에서도 표본이 균질하지 않을 경우 전통적인 비대칭 통계 분석이 크게 오차를 과소평가하고 잘못된 결론을 초래할 수 있음을 보여준다. 저자들은 여러 구간으로 표본을 나누어 χ² 검정과 빈도 그래프를 적용함으로써 이질성을 효과적으로 탐지하고, 모든 실험 데이터 분석에 비모수적 동질성 검정을 반드시 포함시켜야 한다고 주장한다.
상세 분석
이 논문은 실험이 비용이 많이 들거나 재현이 어려운 상황에서 얻어지는 제한된 표본이 실제로는 내부 프로토콜에 의해 여러 하위 모집단으로 구성될 가능성을 강조한다. 저자들은 의사난수 생성기를 이용해 두 종류의 내부 규칙을 구현하고, 각각 100 000개 이상의 관측값을 수집하였다. 표면적으로는 전통적인 평균·분산 추정과 신뢰구간 계산이 정상적으로 수행되는 듯 보였지만, 실제 데이터는 두 하위 프로세스가 교차하는 구간에서 확률 분포가 급격히 변한다는 사실을 숨기고 있었다.
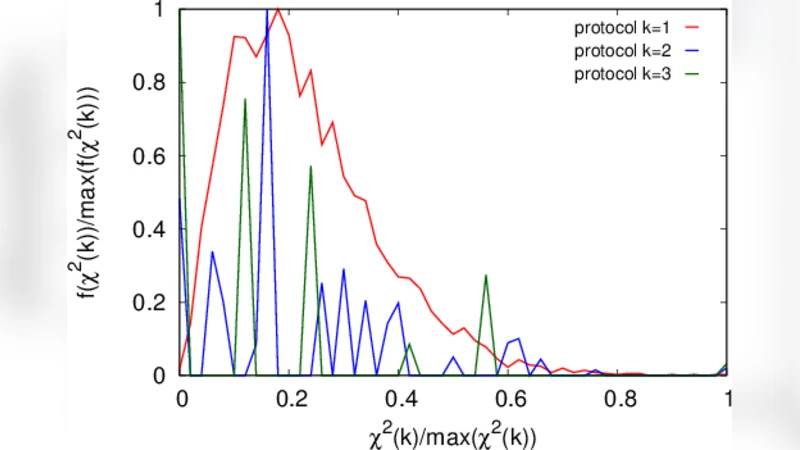
핵심적인 실험 방법은 전체 표본을 임의의 크기로 여러 구간으로 분할한 뒤, 각 구간에 대해 기대 빈도와 관측 빈도를 비교하는 χ² 검정을 수행하는 것이었다. 구간별 χ² 통계량이 유의수준을 크게 초과하는 경우가 빈번히 나타났으며, 특히 표본 앞부분과 뒤부분 사이에 뚜렷한 전이 구간이 존재함을 확인했다. 이러한 전이는 표본 전체에 걸친 평균·분산 추정에 큰 편향을 일으키며, 전통적인 대수적 근사(예: 중심극한정리 기반)에서는 이러한 편향을 잡아내지 못한다는 점을 실증하였다.
또한 저자들은 χ² 빈도 그래프를 시각화함으로써 이질성의 패턴을 직관적으로 파악할 수 있음을 보여준다. 그래프에서 특정 구간에서 급격히 상승하거나 하강하는 빈도 차이는 해당 구간이 다른 모집단에 속함을 시사한다. 이러한 비모수적 검정은 사전 가정이 거의 필요 없으며, 복잡한 내부 프로토콜을 가진 실험 데이터에도 적용 가능하다.
논문의 결론은 두 가지로 요약된다. 첫째, 표본이 충분히 크더라도 내부 이질성이 존재하면 전통적인 비대칭 통계 추정은 신뢰할 수 없으며, 오류 범위가 심각하게 과소평가된다. 둘째, χ² 검정과 같은 간단한 비모수적 동질성 검정을 분석 흐름에 포함시키면 이러한 위험을 사전에 차단할 수 있다. 따라서 실험 설계 단계에서부터 데이터 수집 후 초기 탐색 단계에 이 검정들을 반드시 적용해야 한다는 실용적인 권고를 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기