LHCb 디스크 저장소 최적화를 위한 데이터 인기 예측 알고리즘
초록
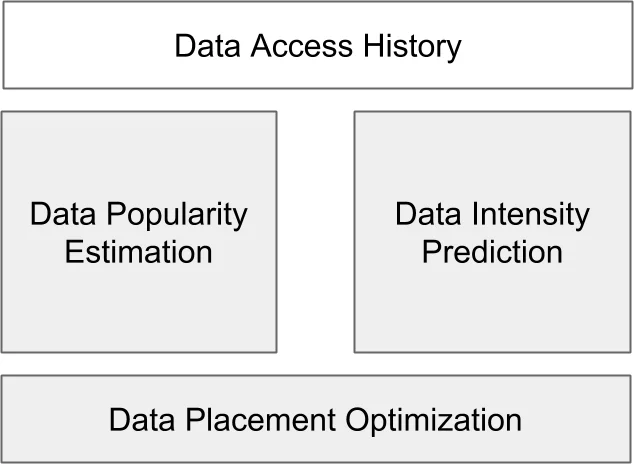
본 논문은 LHCb 실험의 하이브리드 스토리지(테이프 + 디스크)에서 데이터 집합을 효율적으로 배치하기 위해 데이터 사용 이력과 메타데이터를 활용한 머신러닝 기반 인기 예측기와 사용 강도 예측기를 설계하고, 이를 손실 함수 최소화 문제와 결합해 최적의 복제본 수와 디스크 보관 여부를 결정한다. 실험 결과, 제안 알고리즘은 기존 LRU 방식에 비해 디스크 공간 절감률은 비슷하면서도 잘못 삭제된 데이터 수를 크게 줄이고, 전체 다운로드 시간을 최대 30 %까지 단축한다.
상세 분석
이 연구는 LHCb 데이터 관리의 핵심 과제인 “디스크는 비싸고, 테이프는 느리지만 용량이 크다”는 트레이드오프를 수학적 최적화로 풀어낸다. 먼저 데이터 인기 추정 단계에서는 78주간의 사용 이력을 기반으로 26주 최근 사용 여부를 라벨링(인기 = 0, 비인기 = 1)하고, 원시 메타데이터에 ‘주당 사용 횟수’, ‘연속 사용 간격 통계’, ‘질량 중심’ 등 10여 개의 파생 변수를 추가한다. 이러한 특성들은 Gradient Boosting Classifier에 투입되어 각 데이터셋이 미래에 사용되지 않을 확률을 출력한다. 출력 확률은 “비인기” 지표로 변환돼 임계값을 넘는 경우 디스크에서 제거된다.
다음 단계인 사용 강도 예측에서는 데이터가 매우 희소하고 통계량이 부족함을 감안해 비모수적 방법을 채택한다. Nadaraya‑Watson 커널 스무딩을 LO‑O 최적화된 밴드폭(최대 30주)으로 적용하고, 이후 롤링 평균을 구해 주간 사용 강도 추정값을 얻는다. 이 두 단계는 서로 독립적으로 수행되지만, 최종 최적화에서는 인기 확률과 예측 강도가 동시에 고려된다.
핵심은 손실 함수 L = C_disk·∑S_i(Rp_i+αI_iRp_i)δ_i + C_tape·∑S_i(1−δ_i) + C_miss·∑S_i m_i이다. 여기서 δ_i는 디스크 보관 여부, Rp_i는 복제본 수, I_i는 예측 사용 강도, α는 복제본 부족에 대한 페널티이다. 첫 번째 항은 디스크 비용과 복제본 수에 따른 가중치를, 두 번째 항은 테이프 저장 비용을, 세 번째 항은 잘못 삭제된 데이터를 복구하는 비용을 반영한다. 복제본 수는 Rp_i^opt = √(α·I_i) 로 정의되어 사용 강도가 클수록 복제본을 늘리도록 설계되었다.
실험에서는 7 375개의 데이터셋(78주 이전에 생성·첫 사용된)으로 LRU와 비교하였다. 파라미터 C_disk = 100, C_tape = 1, C_miss = 2000 등 디스크 비용을 크게 부각시킨 설정에서, 제안 알고리즘은 최대 복제본 수를 4로 제한했을 때 다운로드 시간 비율을 0.96 ~ 0.99 수준으로 유지하면서 잘못 삭제된 데이터 수를 9개로 크게 감소시켰다. 복제본 수를 7까지 허용하면 디스크 공간 절감률이 40 %에 달하고, 다운로드 시간은 30 %까지 단축되었다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 희소한 사용 이력에도 불구하고 비모수적 스무딩과 풍부한 파생 특성을 결합하면 충분히 신뢰할 만한 인기·강도 예측이 가능하다는 점이다. 둘째, 비용 기반 손실 함수를 명시적으로 모델링함으로써 디스크·테이프·복구 비용을 동시에 최소화하는 다목적 최적화를 구현할 수 있다. 특히 α 파라미터를 조정함으로써 복제본 수와 접근 지연 사이의 균형을 유연하게 맞출 수 있다. 향후 연구에서는 실시간 스트리밍 데이터와 동적 비용 모델을 도입해 적응형 최적화 프레임워크로 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기