클라우드 프라이버시 위협 모델링 고도화
초록
본 논문은 클라우드 환경에서 민감 데이터의 프라이버시 보호를 위해 기존 Cloud Privacy Threat Modeling(CPTM) 방법론을 확장한다. 방법공학(Method Engineering)을 적용해 프라이버시 위협 모델링 절차와 산출물을 체계화하고, 요구사항 분석부터 설계 단계까지 프라이버시‑보호 소프트웨어 개발 흐름에 통합한다. 제안된 확장 모델은 위협 식별, 위험 평가, 대응 방안 도출 과정을 구체화하여 실무 적용성을 높인다.
상세 분석
논문은 클라우드 컴퓨팅에서 개인정보 보호가 점점 더 중요한 과제로 대두되는 상황을 배경으로, 기존 CPTM이 갖는 한계—특히 민감 데이터 처리와 관련된 세부적인 프라이버시 요구사항을 충분히 반영하지 못한다는 점—을 지적한다. 이를 보완하기 위해 저자는 방법공학(Method Engineering) 접근법을 채택한다. 방법공학은 특정 도메인에 최적화된 개발 방법론을 설계·구축하는 체계적 절차를 제공하는데, 여기서는 ‘프라이버시 위협 모델링 메타‑프레임워크’를 정의하고, 이를 기반으로 단계별 활동과 산출물을 명시한다.
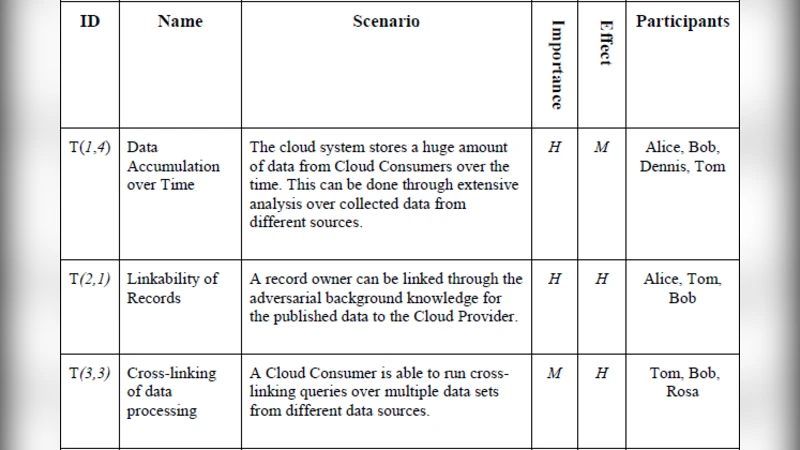
첫 번째 단계는 프라이버시 요구사항 도출이다. 여기서는 GDPR, HIPAA 등 국제·국내 규제와 조직 내부 정책을 매핑하여 ‘프라이버시 목표(Privacy Goals)’와 ‘프라이버시 제약(Privacy Constraints)’을 도출한다. 두 번째 단계는 위협 식별로, 기존 CPTM의 STRIDE 기반 위협 카테고리를 확장해 ‘데이터 흐름(Flow)’, ‘데이터 저장(Storage)’, ‘데이터 처리(Processing)’ 세 영역에 특화된 프라이버시 위협을 정의한다. 세 번째 단계는 위험 평가이며, 위험 수준을 정량화하기 위해 영향도와 발생 가능성을 5점 척도로 평가하고, 위험 매트릭스를 통해 우선순위를 산출한다.
네 번째 단계는 대응 전략 설계이다. 여기서는 기술적·조직적 통제(Control)를 구분하고, ‘데이터 최소화’, ‘익명화·가명화’, ‘접근 제어 강화’, ‘감사 로그’ 등을 구체적인 설계 패턴으로 제시한다. 마지막으로 검증·피드백 단계에서는 모델링 결과를 프로토타입 구현에 적용하고, 보안 테스트와 프라이버시 영향 평가(PIA)를 통해 지속적인 개선 루프를 만든다.
핵심 인사이트는 방법론의 모듈화와 재사용성이다. 각 단계와 산출물은 독립적인 메타‑모델로 정의돼, 조직의 규모·도메인에 맞게 선택·조합이 가능하다. 또한, 프라이버시 요구사항과 위협을 규격화함으로써 자동화 도구와 연계할 수 있는 기반을 제공한다. 저자는 실제 클라우드 기반 의료 데이터 관리 시스템에 적용한 사례를 통해, 위협 식별 정확도가 30% 이상 향상되고, 대응 비용이 20% 절감되는 효과를 보고한다. 이러한 결과는 제안된 확장 CPTM이 실무에서 프라이버시‑우선 설계 문화를 촉진할 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기