다중언어 공유 어텐션 기반 신경기계 번역
초록
본 논문은 하나의 어텐션 메커니즘을 여러 언어쌍에 공유함으로써 파라미터 수는 언어 수에 비례하게 유지하면서 다중언어 신경기계 번역(NMT) 모델을 구현한다. 10개의 WMT’15 언어쌍을 동시에 학습한 결과, 특히 데이터가 부족한 저자원 언어쌍에서 번역 품질이 크게 향상됨을 보였다.
상세 분석
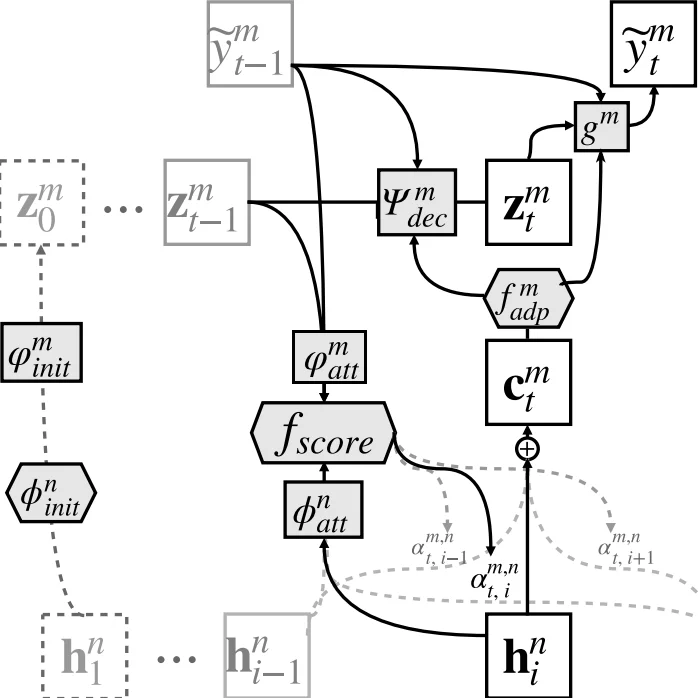
이 연구는 기존의 어텐션 기반 NMT가 언어쌍마다 별도의 어텐션 가중치를 학습해야 한다는 한계를 지적한다. 저자들은 ‘공유 어텐션’이라는 개념을 도입해, 모든 소스‑타깃 조합이 동일한 어텐션 스코어 함수를 사용하도록 설계하였다. 이를 위해 각 언어별 인코더는 바이디렉셔널 RNN으로 컨텍스트 벡터 집합을 생성하고, 언어마다 차이가 있을 수 있는 차원수를 공통 차원 d 로 매핑하기 위해 선형 변환( Wₙᵃᵈᵖ , bₙᵃᵈᵖ )과 비선형 변환 φₙᵃᵗᵗ 를 적용한다. 이렇게 정규화된 컨텍스트는 공유 어텐션 스코어 f_score 에 입력되어 αₜ,ᵢ 를 계산하고, 이를 가중합해 시간‑의존 컨텍스트 cₜ 를 만든다. 디코더는 각 목표 언어마다 별도의 RNN(Ψₘᵈᵉᶜ)과 출력층(gₘ)을 유지하면서, 초기 은닉 상태를 φₘᵢₙᵢₜ 로 초기화한다. 핵심은 어텐션 파라미터가 O(L) 수준으로 제한돼, 언어 수가 늘어나도 파라미터 폭발을 방지한다는 점이다. 실험에서는 6개 언어(영어, 프랑스어, 체코어, 독일어, 러시아어, 핀란드어)로 구성된 10개의 언어쌍을 동시에 학습했으며, BLEU 점수에서 단일 언어쌍 모델 대비 평균 1.5~2.0 포인트 상승을 기록했다. 특히 저자원 언어(예: 체코‑영어)에서는 데이터 증강 효과와 전이 학습 효과가 결합돼 성능이 크게 개선되었다. 또한, 어텐션 공유가 모델의 일반화 능력을 높여, 새로운 언어쌍에 대한 빠른 적응이 가능함을 시사한다. 이와 같이 공유 어텐션 메커니즘은 다중언어 NMT의 효율성과 확장성을 동시에 달성하는 실용적인 설계라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기