대규모 데이터 분산 머신러닝 전략과 원칙
초록
본 논문은 빅데이터 환경에서 수백만~수십억 파라미터를 갖는 머신러닝 모델을 수십에서 수천 대의 머신에 분산 실행하기 위한 설계 원칙과 실천 전략을 제시한다. 저자는 “어떻게 ML 프로그램을 분산시키고, 계산과 통신을 연결하며, 어떤 방식·무엇을 통신할 것인가”라는 네 가지 핵심 질문을 중심으로, ML 특유의 오류 허용성, 동적 구조 의존성, 비균등 수렴 특성을 분석하고, 이를 반영한 시스템·알고리즘 설계 지침을 도출한다. 또한 기존 데이터플로우·그래프 기반 플랫폼의 장단점을 비교하고, 파라미터 서버와 워크로드 파티셔닝을 결합한 새로운 분산 클러스터 운영 체계를 제안한다.
상세 분석
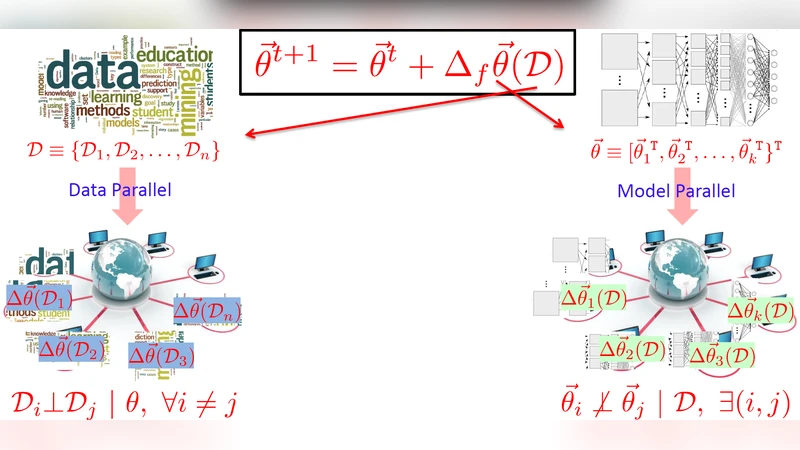
이 논문은 머신러닝 프로그램을 전통적인 트랜잭션 중심 프로그램과 구별하는 세 가지 근본적 특성을 강조한다. 첫째, 오류 허용성(error tolerance) 으로, ML 알고리즘은 근사값에 대해 수렴성을 유지하므로 미세한 수치 오차가 전체 모델 정확도에 큰 영향을 미치지 않는다. 이는 통신 지연이나 패킷 손실을 완화하는 비동기식 업데이트 설계에 유리하게 작용한다. 둘째, 동적 구조 의존성(dynamic structural dependencies) 은 파라미터 간 상관관계가 학습 진행 중에 지속적으로 변한다는 점을 의미한다. 따라서 정적 파티션보다 파라미터 간 의존성을 실시간으로 탐지하고, 의존도가 높은 파라미터를 같은 노드에 배치하거나, 의존성이 낮은 파라미터를 분산시키는 전략이 필요하다. 셋째, 비균등 수렴(non‑uniform convergence) 은 일부 파라미터는 몇 번의 업데이트만으로 수렴하지만, 다른 파라미터는 수백 번의 반복이 요구된다는 사실이다. 이 특성을 활용하면, 빠르게 수렴한 파라미터에 대한 통신 빈도를 낮추고, 아직 수렴하지 않은 파라미터에만 집중적인 동기화·전파를 수행함으로써 전체 시스템 스루풋을 크게 향상시킬 수 있다.
논문은 이러한 특성을 바탕으로 네 가지 설계 질문에 대한 구체적 해답을 제시한다. 1) 분산 방법에서는 파라미터 서버 모델을 기본 골격으로 삼되, 데이터와 파라미터를 계층적으로 파티셔닝하고, 작업 단위(예: 미니배치, 좌표 블록)를 동적으로 스케줄링한다. 2) 계산‑통신 연결에서는 ‘계산 중심’과 ‘통신 중심’ 사이의 경계선을 명확히 정의하고, 계산이 충분히 진행된 후에만 통신을 트리거하는 ‘연산‑후‑통신’ 패턴을 권장한다. 3) 통신 방식에서는 완전 동기화(BSP)보다 파이프라인화된 비동기 혹은 제한된 일관성 모델(SSP)을 도입해 네트워크 대기시간을 최소화한다. 4) 통신 내용에서는 전체 파라미터를 전송하기보다, 변화량(Δ)이나 스파스 업데이트만을 전송하는 ‘델타 전송’ 전략을 강조한다. 이러한 설계는 기존 Hadoop/Spark와 같은 BSP 기반 데이터플로우 시스템이 겪는 병목을 회피하고, GraphLab과 같은 정점 프로그래밍 모델이 요구하는 복잡한 변환 작업을 최소화한다.
또한 논문은 Lasso 회귀와 토픽 모델링을 사례로 들어, 좌표 하강법과 확률적 그래디언트 디센트가 각각 어떻게 파라미터 서버와 결합될 수 있는지를 상세히 설명한다. 특히, 좌표 하강법에서는 파라미터가 독립적인 블록으로 나뉘어 각 워커가 로컬 업데이트 후 중앙 서버에 스파스 Δ만을 전송함으로써 통신 비용을 O(1) 수준으로 낮출 수 있음을 실험적으로 입증한다. 전체적으로 이 논문은 ML 알고리즘의 수학적 특성과 클러스터 하드웨어의 물리적 제약을 동시에 고려한 ‘ML‑centric 시스템 설계’라는 새로운 패러다임을 제시한다는 점에서 학술적·실무적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기