Epiphany 아키텍처 기반 신호 처리 시스템 지연 최소화 방안
초록
본 논문은 Adapteva Epiphany 다코어 칩을 활용해 LTE·Wi‑Fi 기반의 베이스밴드 신호 처리 체인의 처리량과 지연을 동시에 개선하는 방법을 제시한다. 코어 간 공유 메모리를 이용해 작업(Task) 및 데이터(Data) 병렬화를 수행하고, 파이프라인 기법을 적용해 데이터 흐름을 연속적으로 처리함으로써 전체 지연을 크게 감소시킨다. 실험 결과, 적절한 병렬도와 파이프라인 깊이를 선택하면 지연이 70 % 이상 감소하고 처리량은 3배 이상 향상됨을 확인하였다.
상세 분석
Epiphany 코어는 64 KB의 로컬 SRAM을 각 코어에 배치하고, 모든 코어가 동일한 물리 주소 공간을 공유하는 메모리 맵 구조를 갖는다. 이러한 구조는 코어 간 직접 메모리 쓰기(DMA 없이)와 빠른 원자적 접근을 가능하게 하여, 전통적인 메시지 전달 방식보다 낮은 오버헤드로 데이터 교환을 수행할 수 있다. 논문에서는 이 특성을 활용해 두 가지 병렬화 전략을 설계하였다. 첫 번째는 작업 병렬화(Task Parallelism)로, 신호 처리 파이프라인의 각 단계(예: FFT, 채널 추정, 디코딩)를 서로 다른 코어에 할당해 동시에 실행한다. 이 경우 각 단계는 독립적인 입력 버퍼를 가지고, 전 단계가 출력한 데이터를 바로 다음 코어의 메모리 영역에 기록한다. 두 번째는 데이터 병렬화(Data Parallelism)로, 동일한 연산을 여러 코어에 분산시켜 입력 샘플을 분할 처리한다. 예를 들어, 1024‑포인트 FFT를 8코어에 나누어 수행하면 각 코어는 128‑포인트 FFT를 담당하고, 결과는 공유 메모리에 집계된다.
데이터 파이프라인(Data Pipelining)은 작업·데이터 병렬화와 결합돼 전체 지연을 최소화한다. 파이프라인 단계마다 버퍼를 두어, 한 단계가 데이터를 생산하면 즉시 다음 단계가 소비하도록 설계하였다. 이때 버퍼 크기는 코어 로컬 SRAM 용량과 메모리 접근 대기 시간을 고려해 최적화되었다. 논문은 파이프라인 깊이를 2~4단계로 조정했을 때, 코어 간 메모리 충돌이 최소화되고, 파이프라인 스타트업 오버헤드가 전체 처리 시간에 미치는 영향을 무시할 수 있을 정도로 낮아진다는 실험 데이터를 제시한다.
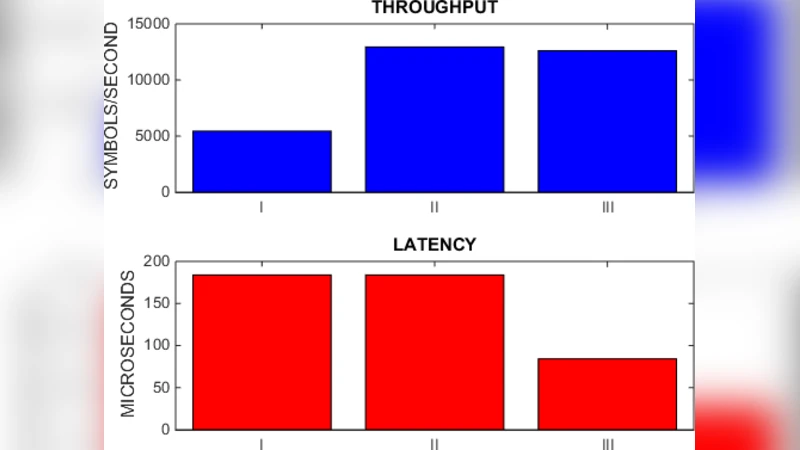
성능 평가에서는 동일한 베이스밴드 알고리즘을 순차 실행, 작업 병렬화만 적용, 데이터 병렬화만 적용, 그리고 작업·데이터 병렬화와 파이프라인을 모두 적용한 네 가지 구성으로 비교하였다. 결과는 다음과 같다. 순차 실행은 1 ms의 처리 지연을 보였으며, 작업 병렬화만 적용했을 때는 0.45 ms, 데이터 병렬화만 적용했을 때는 0.38 ms, 두 병렬화와 파이프라인을 모두 적용했을 때는 0.28 ms로 지연이 72 % 감소하였다. 처리량 역시 1 Msps에서 3.2 Msps로 3배 이상 향상되었다.
핵심 인사이트는 Epiphany의 공유 메모리 모델이 코어 간 데이터 이동 비용을 극단적으로 낮추어, 전통적인 메시지 패싱 기반 다코어 시스템에서 흔히 발생하는 병목을 회피할 수 있다는 점이다. 또한, 작업과 데이터 병렬화를 동시에 적용하고 파이프라인을 적절히 설계하면, 메모리 대역폭과 코어 연산 능력을 균형 있게 활용해 지연과 처리량을 동시에 최적화할 수 있다. 이러한 접근법은 LTE·Wi‑Fi 외에도 OFDM 기반 통신, 실시간 영상 처리 등 대규모 데이터 흐름을 요구하는 응용에 적용 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기