듣고 주목하고 걸어라 네비게이션 명령을 행동 시퀀스로 매핑하는 신경망
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
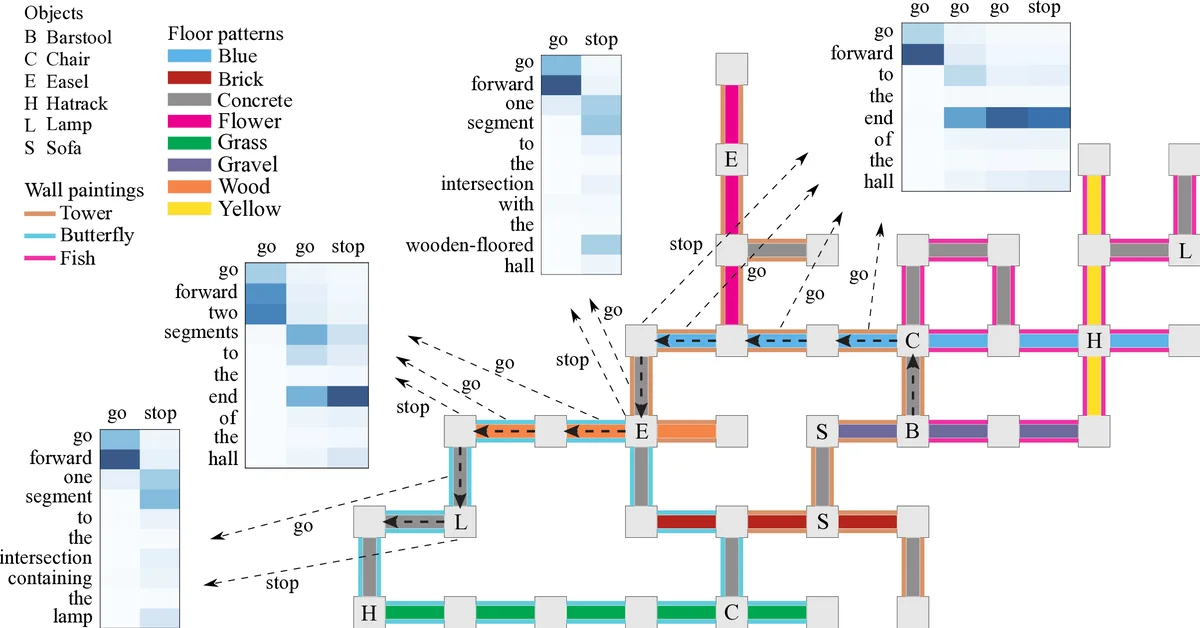
본 논문은 자연어 형태의 이동 지시문을 로봇이 실행할 수 있는 행동 시퀀스로 변환하는 엔코더‑디코더 구조의 LSTM 기반 모델을 제안한다. 다중 수준 어텐션 메커니즘을 도입해 원문 단어와 고수준 은닉 표현을 동시에 활용함으로써 현재 관측된 세계 상태와 연관된 문장 부분에 집중한다. 별도의 파서나 사전 정의된 어휘 사전 없이도 단일 문장 데이터셋에서 최고 성능을 달성하고, 제한된 학습 데이터가 있는 다문장 상황에서도 경쟁력 있는 결과를 보인다.
상세 분석
이 연구는 로봇이 인간의 자유형 언어 지시를 이해하고 실행하는 문제를 순차‑순차 매핑으로 정의하고, 이를 신경망 기반 시퀀스‑투‑시퀀스 학습으로 해결한다. 핵심은 세 가지 요소다. 첫째, 양방향 LSTM 인코더는 입력 문장을 전·후 방향으로 동시에 처리해 각 단어에 대한 풍부한 컨텍스트 정보를 담은 은닉 벡터 hₖ를 생성한다. 둘째, 기존 어텐션이 고수준 은닉 상태만을 가중합하는 데 반해, 저자들은 원-핫 단어 벡터 xₖ와 은닉 상태 hₖ를 동시에 고려하는 다중‑수준 어텐션을 설계했다. 이는 βₜⱼ = vᵀ tanh(W·sₜ₋₁ + U·xⱼ + V·hⱼ) 형태의 점수를 통해 각 단어와 그 주변 컨텍스트가 현재 디코더 상태와 얼마나 일치하는지를 정량화하고, αₜⱼ = exp(βₜⱼ)/∑ⱼ exp(βₜⱼ) 로 정규화한다. 이렇게 얻은 가중합 zₜ = Σⱼ αₜⱼ·
댓글 및 학술 토론
Loading comments...
의견 남기기