SIMD 아키텍처를 위한 적응형 대수 멀티그리드 최적화
초록
본 논문은 Wuppertal에서 개발한 적응형 대수 멀티그리드(DD‑α AMG) 코드를 Intel Xeon Phi(KNC)와 같은 SIMD 기반 프로세서에 최적화한 구현 방식을 제시한다. 기존에 KNC용 도메인‑분할 스무더를 재사용하고, 제한·보강 연산, 코어 그리드 연산자 구성, 그램‑슈미트 정규화 등을 테스트 벡터 수(N_tv)를 SIMD 길이와 맞추어 벡터화하였다. 결과적으로 제한·보강, 코어 그리드 연산자 설정 등 주요 단계에서 10배‑20배의 속도 향상을 달성했으며, 현재는 코어 그리드 솔버의 통신 비용이 전체 실행 시간의 주된 병목으로 남는다.
상세 분석
이 연구는 적응형 대수 멀티그리드(Adaptive Algebraic Multigrid, AMG) 기법을 SIMD 아키텍처에 효율적으로 이식하기 위한 일련의 최적화 전략을 상세히 기술한다. 먼저, 외부 선형 방정식 해법으로 FGMRES를 사용하고, 프리컨디셔너로 DD‑α AMG를 적용한다. DD‑α AMG는 저주파 모드 억제를 위한 코어 그리드 보정(V‑cycle)과 고주파 모드 억제를 위한 도메인‑분할(Domain‑Decomposition) 스무더로 구성된다. 본 논문에서는 KNC(Knights Corner)용으로 이미 최적화된 스무더 코드를 그대로 활용하고, 나머지 단계—특히 제한(Restriction), 보강(Prolongation), 코어 그리드 연산자(D_c) 구축, 그리고 테스트 벡터에 대한 그램‑슈미트 정규화—를 SIMD 친화적으로 재구현한다.
핵심 아이디어는 테스트 벡터 수 N_tv를 SIMD 레지스터 길이 N_SIMD(단정밀도 16)와 정수 배수 관계로 맞추어, 행렬‑벡터 곱을 N_tv개의 벡터를 동시에 처리하도록 하는 것이다. 제한 연산에서는 R 행렬의 행을 SIMD 벡터에 로드하고, 복소수 연산을 4개의 실수 fmadd로 구현한다. 보강 연산은 전치된 R(=P†)를 사용하므로 열 인덱스를 SIMD에 매핑하고, 마지막에 SIMD 내부 합산을 수행한다. 코어 그리드 연산자 구축에서는 D_hh^0·P 연산을 각 블록 내부에서 μ‑방향 링크와 클로버 행렬을 이용해 복합 fmadd로 구현하고, 전치 연산을 최소화하기 위해 D_c를 직접 저장한다. 또한, 메모리 대역폭 절감을 위해 D_c를 반정밀도(half‑precision)로 저장했으며, 이는 수치 안정성에 영향을 주지 않았다.
벡터화된 그램‑슈미트는 클래식 방식을 채택하고, 블록 그램‑슈미트 기법을 이용해 캐시 재사용을 극대화했다. 다만, axpy와 내적 연산에서 SIMD 벡터의 절반이 비활용되는 비효율이 존재한다. 코어 그리드 수준의 BLAS‑유사 연산은 데이터 레이아웃을 변경하지 않고, 필요 시 실시간으로 실수·허수 부분을 디인터리브하여 SIMD 연산을 수행한다.
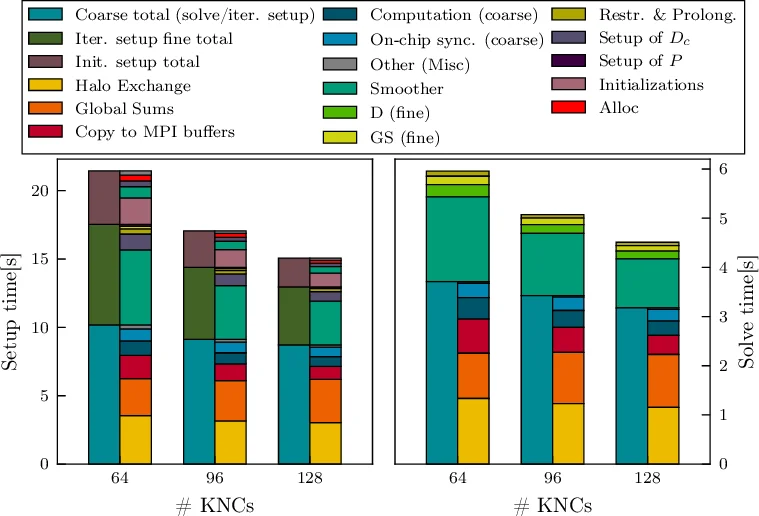
성능 평가에서는 단일 KNC 코어에서 제한·보강·D_c 설정 단계가 각각 14.1배, 8.6배, 19.7배의 속도 향상을 보였으며, 전체 MG 프리컨디셔너에서 이들 단계가 차지하는 비중이 크게 감소했다. 현재 남아 있는 주요 비용은 스무더와 코어 그리드 솔버의 통신(halo exchange, global sums)이며, 이는 향후 통신 최적화가 필요함을 시사한다. 최종적으로 DD‑α AMG는 SIMD 기반 시스템에서 매우 효율적인 프리컨디셔너임이 입증되었다.
댓글 및 학술 토론
Loading comments...
의견 남기기