다음 세대 데이터 병렬 QCD 라이브러리 Grid
초록
Grid는 최신 슈퍼컴퓨터의 다중코어·다중벡터 아키텍처에 최적화된 C++11 기반 데이터 병렬 라이브러리이다. SIMD 추상화, 가상 노드 과분해, 템플릿 메타프로그래밍을 통해 벡터 길이에 독립적인 고성능 코드를 자동 생성하고, MPI·OpenMP·SIMD를 일관되게 결합한다. 실험 결과, 캐시 내 데이터에 대해 65 % 이상의 피크 성능을 달성한다.
상세 분석
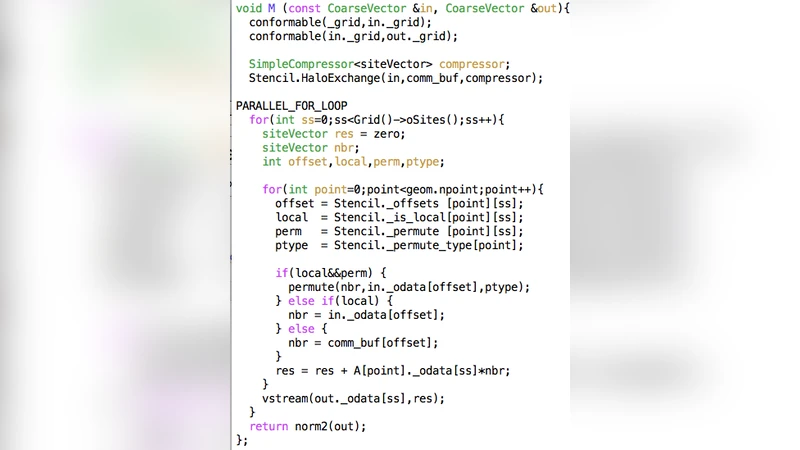
Grid 라이브러리는 기존 QDP++와 달리 “타입 시스템 자체를 고성능으로 설계”한다는 근본적인 접근 방식을 취한다. 가장 핵심적인 설계는 SIMD 연산을 C++11 클래스(vRealF, vRealD, vComplexF, vComplexD, vInteger)로 캡슐화하고, 각 아키텍처별 인트린식 함수를 내부에 숨겨 사용자 코드에서는 순수한 연산자 오버로드만 사용하도록 만든 점이다. 이를 위해 Nsimd()라는 정적 멤버 함수를 통해 현재 컴파일 타깃의 벡터 길이를 런타임이 아닌 컴파일 타임에 알려 주어, 템플릿 전개와 루프 언롤링이 자동으로 이루어진다.
또 다른 혁신은 “가상 노드 과분해(over‑decomposition)”이다. 물리적 MPI 노드당 SIMD 레인 수에 맞추어 격자를 가상 노드로 분할하고, 서로 다른 가상 노드의 데이터를 인접 SIMD 레인에 교차 배치한다. 이렇게 하면 3×3 색 행렬·벡터와 같이 자연적으로 SIMD 길이에 맞지 않는 구조도, 여러 가상 노드의 연산을 동시에 수행함으로써 100 % SIMD 효율을 얻을 수 있다. 예를 들어 AVX‑512 환경에서 512비트 레인은 8개의 복소수(double) 혹은 16개의 복소수(float)를 담을 수 있는데, 하나의 행렬‑벡터 곱을 수행하면 가로 합산(horizontal reduction)으로 인한 파이프라인 지연이 발생한다. Grid는 Nsimd()개의 행렬‑벡터 곱을 동시에 처리하도록 데이터 레이아웃을 변형함으로써 이러한 가로 합산을 완전히 회피한다.
MPI와 OpenMP의 혼합 사용도 자연스럽게 지원한다. Grid 객체는 차원, MPI 분할, OpenMP 스레드 수, SIMD 레인 수를 모두 포함하는 메타데이터를 보유하고, Lattice 컨테이너는 내부 레이아웃을 은닉한다. 따라서 고수준 코드에서는 “A = B * C”와 같은 연산만 작성하면 되고, 내부적으로는 MPI halo 교환, OpenMP 스레드 워크쉐어, SIMD 벡터 연산이 동시에 일어난다. 특히 cshift 연산은 스테레오 타입의 순환 이동을 SIMD 레인 간에 최소한의 permutation만으로 구현해, 표면‑부피 비율이 높은 격자 연산에서 오버헤드를 사실상 무시할 수 있게 만든다.
성능 측면에서는 Intel Xeon Skylake, KNL 등 최신 x86‑64 아키텍처에서 캐시 내 데이터에 대해 60 %~65 % 피크 플롭스를 기록했으며, 이는 전통적인 scalar 코드 대비 4배 이상 향상된 수치이다. 또한 새로운 SIMD 집합(AVX‑512, IMCI 등)에 대한 포팅은 약 300줄의 코드만 추가하면 되므로, 향후 ARM Neon이나 GPU 기반 벡터에도 빠르게 확장 가능하다.
요약하면, Grid는 “벡터 길이와 아키텍처에 독립적인 고수준 데이터 병렬 인터페이스”를 제공하면서, 내부 구현에서는 SIMD 추상화, 가상 노드 과분해, 템플릿 기반 자동 언롤링 등을 활용해 최적의 하드웨어 활용도를 달성한다. 이는 차세대 초고성능 컴퓨팅 환경에서 Lattice QCD와 같은 복잡한 수치 시뮬레이션 코드를 재작성 없이도 지속 가능한 성능을 얻을 수 있게 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기