부분 재초기화를 이용한 최적화 기법의 효율 향상
초록
본 논문은 전통적인 전역 재시작 방식의 한계를 극복하고자, 변수의 일부만을 선택적으로 재초기화하는 “부분 재초기화” 기법을 제안한다. 계층적 재초기화 전략을 통해 이전 실행에서 얻은 정보를 유지하면서도 지역 최적점에 머무르는 문제를 완화한다. HMM 학습, k‑means 및 k‑medoids 클러스터링 등 여러 머신러닝 과제에 적용한 실험 결과, 동일 시간·연산량 대비 최종 비용이 크게 감소하고 수렴 속도가 향상됨을 확인하였다.
상세 분석
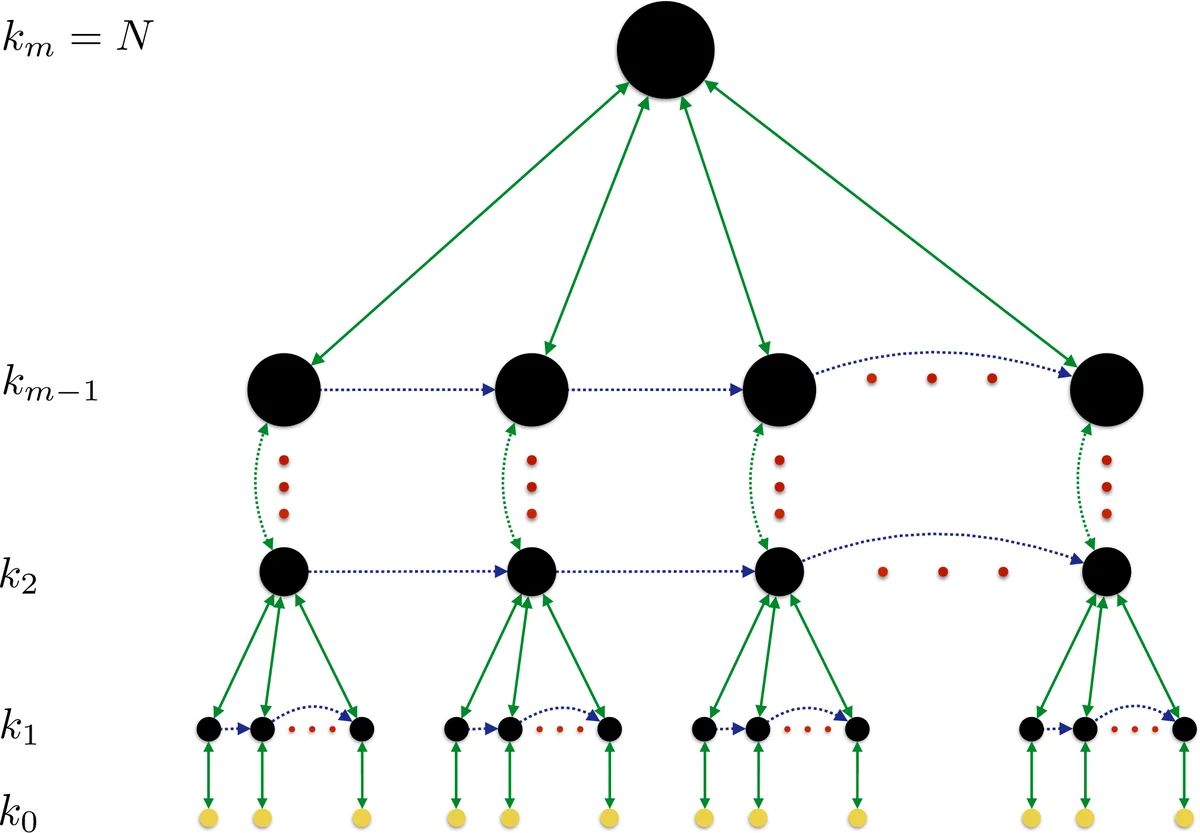
논문은 먼저 기존의 휴리스틱 최적화기가 지역 최적점에 갇히는 현상을 지적하고, 이를 해소하기 위한 전통적 방법인 전역 재시작이 “정보 손실”이라는 근본적인 문제를 안고 있음을 강조한다. 이를 보완하기 위해 제안된 부분 재초기화는 변수 집합을 계층적으로 정의하고, 각 레벨 l 에서 k_l 개의 변수를 무작위 혹은 문제 특화 히스토리 기반으로 재초기화한다. 재초기화 후에는 하위 레벨 (l‑1) 의 최적화기를 호출해 부분 최적화를 수행하고, 개선이 없을 경우 이전 체크포인트로 복귀한다. 이 과정은 k_m = N (전체 변수 수) 에 도달할 때까지 반복되며, 이론적으로는 전역 최적점에 도달할 확률을 크게 높인다.
알고리즘 복잡도는 각 레벨 l 당 M_l 번의 재초기화와 Q_l 번의 최적화 호출에 비례해 O(∑_l Q_l M_l) 이며, M_l 의 선택은 확률적 최적성 k_l‑optimal 을 보장하도록 로그 스케일로 설정한다(식 (2)). 특히 P (재초기화가 개선을 가져올 확률)이 충분히 큰 구조적 문제에서는 M_l 이 로그 수준으로 충분하지만, 무작위 탐색에 가까운 경우에는 지수적 비용이 요구될 수 있음을 명시한다.
실험에서는 세 가지 대표적인 머신러닝 과제에 부분 재초기화를 적용하였다. 첫 번째는 128‑bit 이진 시퀀스를 학습하는 HMM(바움‑웰치)이며, 전체 재시작 대비 k_1 = 8 개의 변수를 M_1 ≈ 8000 번 재초기화함으로써 로그 가능도가 급격히 상승했다. 두 번째는 7500개의 샘플을 50개의 클러스터로 나누는 k‑means 문제로, 각 전역 재시작마다 단일 클러스터 중심을 M_1 ≈ 100 번 재초기화했을 때, 동일 시간 내에 더 낮은 WCSS를 달성했다. 세 번째는 k‑medoids(PAM) 알고리즘에 적용했으며, 부분 재초기화가 특히 초기 비용이 높은 구간에서 전역 재시작보다 효율적이었다. 전체적으로 부분 재초기화는 초기 탐색 단계에서는 전역 재시작보다 느릴 수 있으나, 목표 비용이 낮아질수록 수렴 속도가 크게 개선되는 패턴을 보였다.
이러한 결과는 변수 간 상호 의존성이 높은 문제에서 부분 재초기화가 “제약 감소” 효과를 통해 지역 최적점 탈출을 용이하게 만든다는 중요한 통찰을 제공한다. 또한, 히스토리 기반 변수 선택(예: 변수 간 상관관계가 높은 집합 선택)과 결합하면 더욱 높은 성공률을 기대할 수 있다. 논문은 부분 재초기화가 기존 최적화 파이프라인에 최소한의 코드 변경만으로 적용 가능함을 강조하며, 특히 시뮬레이티드 어닐링, 진화 알고리즘 등 다양한 휴리스틱에 일반화될 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기