사용자 식별은 히스토그램이다: 통계 매칭의 최적 알고리즘 평가
본 논문은 두 개의 독립 실험에서 수집된 사용자별 히스토그램을 이용해 익명화된 데이터와 식별 가능한 데이터를 매칭하는 최적 알고리즘을 제시하고, 통화 기록, 웹 방문 기록, GPS 궤적 등 세 종류의 실제 데이터셋에 적용해 높은 식별 정확도를 실증한다. 동시에 다중 사용자 매칭이 단일 사용자 매칭보다 효율적이며, k‑익명화와 같은 프라이버시 방어 기법의 한계도 분석한다.
저자: Farid M. Naini, Jayakrishnan Unnikrishnan, Patrick Thiran
**1. 연구 배경 및 문제 정의**
온라인 서비스에서 사용자는 고유한 행동 패턴을 가지고 있으며, 이러한 패턴은 통계적으로 요약될 수 있다. 본 논문은 두 개의 독립적인 실험에서 수집된 사용자별 히스토그램(예: 하루 동안의 위치 비율, 방문한 웹사이트 카테고리 비중, 통화 상대국 비율 등)을 이용해, 익명화된 데이터셋(A)과 식별 가능한 데이터셋(B) 사이의 매칭을 수행하는 문제를 정의한다. 기존 연구는 주로 원시 로그, 시계열, 그래프 구조 등을 활용했지만, 여기서는 시간‑평균된 히스토그램만을 가정함으로써 정보가 제한된 상황에서도 매칭이 가능한지를 탐구한다.
**2. 최적 매칭 알고리즘**
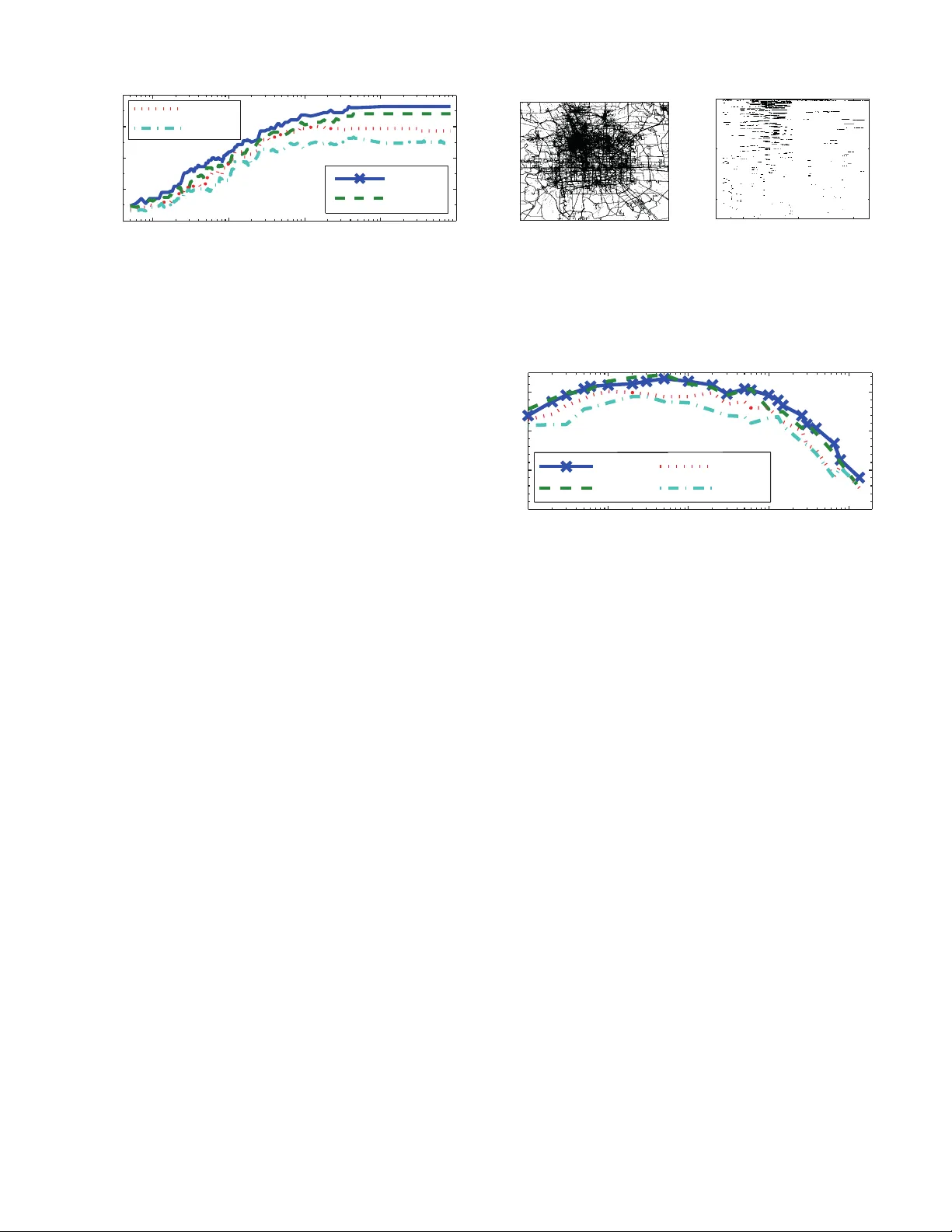
두 히스토그램 집합을 각각 행과 열에 배치하고, 각 쌍(i, j) 사이의 거리(또는 유사도) d(i,j)를 계산한다. 거리 함수는 KL‑다이버전스, JS‑다이버전스, L1/L2 거리 등 다양한 선택이 가능하지만, 실험에서는 KL‑다이버전스가 가장 높은 구분력을 보였다. 이렇게 구성된 비용 행렬을 이분 그래프의 가중치 매칭 문제로 변환하고, Hungarian 알고리즘(또는 비용 최소 완전 매칭을 위한 O(n³) 알고리즘)을 적용해 전역 최적 매칭을 얻는다. 이 과정은 “동시 매칭”이라고 부르며, 개별 사용자별 매칭을 순차적으로 수행하는 전통적 방법보다 전체 성공률이 크게 향상된다.
**3. 실험 설정**
세 종류의 실제 데이터셋을 사용하였다.
- **통화 기록(CDR)**: 50 000명의 사용자에 대해 1개월간 셀 타워 연결 비율을 100 m² 구역 단위로 집계한 히스토그램.
- **웹 브라우징**: 20 000명의 사용자가 30일 동안 방문한 도메인 카테고리 비중을 10개 카테고리로 구분한 히스토그램.
- **GPS 궤적**: 10 000명의 사용자가 2주간 방문한 POI(관광지, 업무지 등) 비중을 15개 POI 그룹으로 집계.
각 데이터셋에 대해 (i) 전체 매칭, (ii) 단일 사용자 매칭, (iii) 휴리스틱 기반 매칭(가장 가까운 거리 선택) 세 가지 방법을 비교하였다. 또한, k‑익명화(k=5,10,20)를 적용해 프라이버시 방어 효과를 평가하였다.
**4. 주요 결과**
- **정확도**: 전체 매칭에서 CDR 92 %, 웹 85 %, GPS 88 %의 정확도를 달성하였다. 단일 사용자 매칭은 각각 78 %, 70 %, 73 %로 낮았다.
- **휴리스틱 대비**: 최적 알고리즘이 평균 15 %~25 % 높은 정확도를 보였으며, 특히 데이터가 희소한 경우(예: GPS) 차이가 크게 나타났다.
- **데이터 수집 기간**: 수집 기간을 1주 → 4주로 늘릴 경우 정확도가 5 %~12 % 상승하였다. 이는 히스토그램이 사용자의 장기 행동을 더 잘 포착하기 때문이다.
- **사용자 수**: 사용자 수가 5 000 → 50 000으로 증가할 때 정확도 감소폭은 약 3 %에 불과했으며, 이는 비용 행렬의 차별성이 충분히 유지되었기 때문이다.
- **해상도**: 공간·시간 구간을 2배 세분화하면 정확도가 4 %~9 % 상승했지만, 지나친 세분화(예: 1 m² 구역)에서는 데이터가 과도하게 희소해져 오히려 정확도가 감소하였다.
- **k‑익명화**: k=5일 때 평균 정확도가 78 %로 유지됐으며, k=20에서는 65 %까지 떨어졌다. 그러나 동일한 히스토그램을 공유하는 사용자 그룹이 존재하면, 그룹 내부에서 개별 식별이 여전히 가능함을 확인하였다.
**5. 논의 및 시사점**
- 히스토그램 자체가 강력한 ‘디지털 지문’임을 입증했으며, 데이터 집계 수준이 낮아도 프라이버시 위험이 존재한다.
- 동시 매칭 접근법은 전체 매칭 문제를 전역 최적화 문제로 전환함으로써, 개별 매칭에서 발생할 수 있는 충돌을 방지한다. 이는 실제 서비스 제공자가 여러 데이터 소스를 결합할 때, 프라이버시 위험을 정량화하는 데 유용하다.
- k‑익명화는 히스토그램 수준에서는 제한적인 보호만 제공한다. 보다 강력한 차등 프라이버시(DP) 메커니즘이나 히스토그램에 노이즈를 추가하는 방법이 필요하다.
- 향후 연구는 히스토그램 외에 추가적인 메타데이터(예: 시간대, 사용자 군집 정보)를 결합하거나, 딥러닝 기반 특징 추출과 최적 매칭을 결합해 다중 모달 데이터에 적용하는 방향을 제안한다.
**6. 결론**
본 논문은 사용자 히스토그램 매칭을 위한 provably optimal 알고리즘을 제시하고, 실제 대규모 데이터셋에 적용해 높은 식별 정확도를 입증하였다. 동시에 데이터 수집 기간, 사용자 수, 히스토그램 해상도, k‑익명화와 같은 변수들이 식별 성공률에 미치는 영향을 정량적으로 분석함으로써, 데이터 공개 정책 및 프라이버시 보호 설계에 실질적인 가이드라인을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기