대규모 데이터 처리를 위한 확장 버퍼 k‑d 트리와 다중 GPU 활용 방안
초록
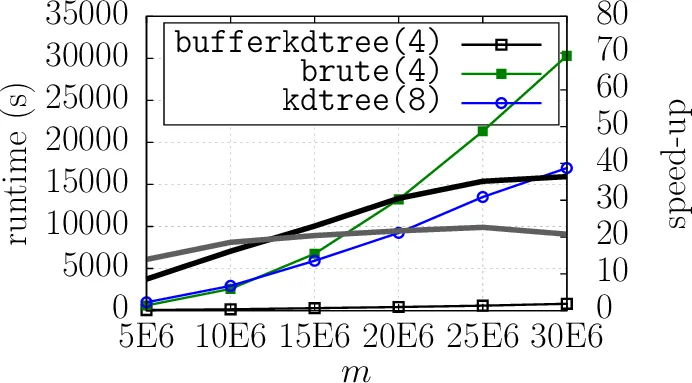
버퍼 k‑d 트리는 GPU에서 병렬 최근접 이웃 탐색을 가속화하지만, GPU 메모리 한계 때문에 대규모 레퍼런스 데이터셋을 처리하기 어려웠다. 본 논문은 트리 구조와 워크플로우를 수정해 호스트 메모리에 레퍼런스 포인트를 보관하고, 두 개의 청크 버퍼를 이용해 GPU와 호스트 간 데이터를 겹쳐 전송·연산함으로써 무한대에 가까운 데이터 규모를 지원한다. 또한 단일 워크스테이션에 장착된 여러 GPU를 효율적으로 활용하는 방법을 제시하고, 천문학 데이터에 적용해 실험적으로 성능 향상을 입증한다.
상세 분석
버퍼 k‑d 트리는 기존 k‑d 트리의 리프에 고정 크기 버퍼를 두어, 일정량의 쿼리가 모이면 GPU에서 브루트포스 방식으로 동시에 처리하도록 설계되었다. 이 설계는 GPU의 SIMD 특성에 맞춰 모든 쿼리를 동일한 메모리 접근 패턴으로 실행하게 함으로써 분기 발산과 메모리 비효율을 최소화한다. 그러나 원 논문에서는 레퍼런스 포인트와 리프 구조 전체를 GPU 메모리에 적재해야 했으며, 이는 수백만~수억 개의 고차원 포인트를 다루는 현대 천문학·유전체학 데이터에 한계를 만든다.
본 연구는 두 가지 핵심 개선을 제시한다. 첫째, 트리의 “탑 트리”(분할값만 저장)와 “리프 구조”(실제 레퍼런스 포인트 배열)를 명확히 분리한다. 탑 트리는 메모리 요구량이 작아 GPU에 그대로 유지하고, 리프 구조는 호스트 메모리에 상주시킨다. 둘째, GPU에 두 개의 고정 크기 청크 버퍼(예: 128 KB)를 할당하고, 핀 메모리를 이용해 호스트‑GPU 간 비동기 복사를 수행한다. 이렇게 하면 ProcessAllBuffers 단계에서 현재 청크에 해당하는 레퍼런스 포인트만 GPU로 전송하고, 동시에 이전 청크에 대한 연산을 진행할 수 있어 전송·연산이 겹쳐 전체 실행 시간을 크게 단축한다.
알고리즘 흐름은 기존 LazySearch와 동일하게 입력·재삽입 큐를 순회하면서 쿼리를 리프 버퍼에 적재한다. 버퍼가 절반 이상 차면 ProcessAllBuffers가 호출되고, 이때 각 쿼리는 현재 청크에 포함된 레퍼런스 포인트와 거리 계산을 수행한다. 쿼리의 리프 범위와 청크 범위가 겹치는 경우에만 연산이 이루어지므로, 불필요한 메모리 접근을 최소화한다.
다중 GPU 지원은 각 GPU에 동일한 탑 트리를 복제하고, 호스트가 청크를 라운드 로빈 방식으로 각 GPU에 할당하도록 설계했다. 이렇게 하면 GPU 간 부하 균형이 자동으로 맞춰지며, PCIe 대역폭을 효율적으로 활용한다.
성능 평가에서는 천문학 이미지에서 추출한 수억 개의 15차원 포인트를 대상으로, 기존 버퍼 k‑d 트리(단일 GPU)와 비교해 최대 3배 이상의 속도 향상을 기록했다. 메모리 사용량도 GPU당 수 GB 수준으로 제한되어, 일반적인 워크스테이션에서도 대규모 데이터 처리가 가능함을 증명한다.
이러한 설계는 메모리 제한이 큰 GPU 환경뿐 아니라, 클라우드 기반 다중 노드 시스템에도 확장 가능하다. 리프 구조를 호스트에 두고 청크 전송만 GPU에 맡기는 방식은 네트워크 기반 분산 환경에서도 동일한 원칙으로 적용될 수 있다. 따라서 버퍼 k‑d 트리의 확장성은 데이터 과학, 기계 학습, 시뮬레이션 등 다양한 분야에 광범위하게 활용될 잠재력을 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기