선형 임베딩 기반 분산 균형 그래프 파티셔닝
초록
본 논문은 대규모 그래프를 k개의 균형 파티션으로 나누어 전체 컷 크기를 최소화하는 분산 알고리즘을 제안한다. 그래프 정점을 일차원 라인에 임베딩한 뒤, 임베딩 순서를 활용해 로컬 스와프, 파티션 경계 최소 컷, 군집 수축·동적 프로그래밍 등 네 가지 후처리 기법을 적용한다. 실험 결과는 기존 라벨 전파, FENNEL, Spinner 등과 비교해 15‑25% 정도 컷 크기를 감소시켰으며, Google Maps 경로 서비스에 적용해 다중 샤드 쿼리를 약 40% 줄였다.
상세 분석
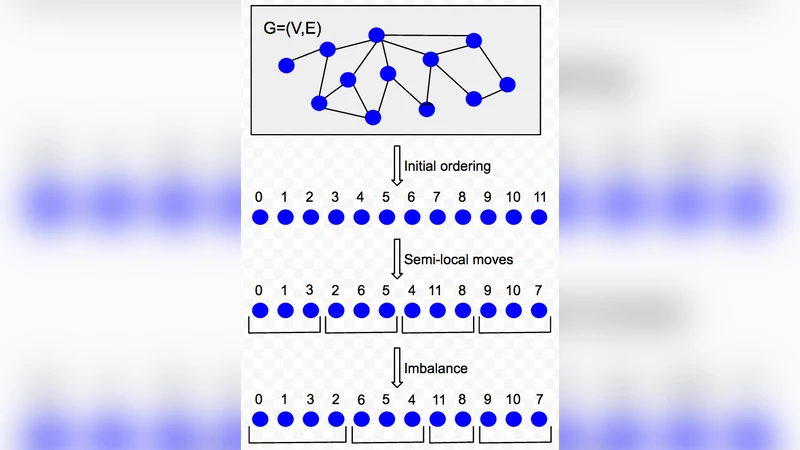
이 연구는 그래프 파티셔닝 문제를 “선형 임베딩 → 순서 기반 후처리”라는 두 단계 파이프라인으로 재구성한다. 첫 단계에서 정점을 라인에 매핑하는 방법으로는 (1) 무작위 순서, (2) 지도 그래프에 특화된 Hilbert 곡선, (3) 공통 이웃 수 기반 계층적 클러스터링, (4) 거리 역수 기반 계층적 클러스터링을 제시한다. 특히, 공통 이웃 기반 계층적 클러스터링은 지도 그래프에서도 가장 낮은 초기 컷을 제공함이 실험을 통해 확인되었다.
후처리 단계에서는 네 가지 기법을 독립적으로 혹은 조합하여 적용한다.
- Local Swaps: 임베딩 순서 상 인접한 정점 쌍을 무작위로 교환하며 컷을 감소시킨다. 이 방법은 트위터와 같은 고밀도 소셜 네트워크에서 효과적이다.
- Boundary Min‑Cut: 각 파티션 경계에 대해 최소 컷을 계산해 경계 정점을 재배치한다. 지도 그래프에서 특히 큰 이득을 보인다.
- Contraction + Dynamic Programming: 경계 최소 컷으로 형성된 군집을 하나의 슈퍼노드로 수축하고, 동적 프로그래밍을 통해 최적 파티션 경계를 찾는다. 이는 파티션 수가 많을수록 스케일러블하게 동작한다.
- Metric Ordering Optimization: 임베딩 순서를 재정렬해 정점 간 거리 메트릭을 최적화한다.
이 네 기법을 순환적으로 적용하는 Combination 알고리즘은 수 차례 반복 후 수렴한다. 실험에서는 수백만 정점·수십억 엣지를 가진 그래프에서도 수 차례 반복만으로 충분히 수렴했으며, 메모리 사용량은 O(|V|+|E|) 수준으로 제한된다.
비교 대상인 라벨 전파(UB13), FENNEL, Spinner, METIS와의 정량적 결과는 다음과 같다. LiveJournal 그래프에서 k=20일 때 컷 비율을 37%→27.5%로 25% 개선했으며, k=100에서는 49%→41.5%로 15% 개선하였다. 트위터 그래프에서는 k>2일 때 METIS와 FENNEL을 모두 앞섰고, k=2에서는 METIS보다 우수하지만 FENNEL보다는 약간 뒤처졌다. Spinner와는 전반적으로 큰 격차를 보였다.
시스템 적용 사례로 Google Maps Driving Directions를 들었다. 지도 그래프에 Hilbert 곡선 기반 초기 파티션을 적용한 뒤, 제안된 컷 최적화 후처리를 수행하면 다중 샤드 쿼리가 21% 감소하고, 실시간 트래픽 실험에서는 40%까지 감소하였다. 이는 CPU 사용량 절감과 서비스 지연 감소로 이어진다.
알고리즘의 장점은 (1) MapReduce·Pregel·Giraph 등 기존 분산 프레임워크에 그대로 구현 가능, (2) 파티션 수 k가 수십에서 수만까지 변동해도 실행 시간과 메모리 요구량이 크게 변하지 않음, (3) 초기 임베딩 선택에 따라 다양한 그래프 유형에 적용 가능하다는 점이다. 한계로는 (i) 최적화 목표가 컷 크기 최소화에만 초점이 맞춰져 있어 파티션 내부의 구조적 품질(예: 커뮤니티 일관성)은 보장되지 않는다, (ii) 정확한 실행 시간과 자원 사용량을 공개하지 못한 점, (iii) 임베딩 단계에서 계층적 클러스터링의 유사도 계산이 대규모 그래프에서는 여전히 비용이 많이 든다. 향후 연구는 스펙트럴 임베딩·그래프 신경망 기반 임베딩을 분산 환경에 적용하거나, 컷 외에 다른 품질 지표(예: 모듈러리티, 지연 시간)를 동시에 최적화하는 다목적 프레임워크를 설계하는 방향으로 진행될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기