가사 언어특성으로 빌보드 상위·하위곡 예측
초록
**
본 논문은 2001‑2010년 빌보드 차트의 가사를 대상으로 261개의 언어학적 특성을 추출하고, 주성분 분석(PCA)으로 차원을 39로 축소한 뒤, 라디얼 커널 SVM으로 상위 30위와 하위 30위 곡을 구분한다. 10‑폴드 교차검증 결과 정밀도·재현율이 0.76, Cohen’s κ가 0.51로, 가사만으로도 히트곡을 어느 정도 예측할 수 있음을 보여준다.
**
상세 분석
**
이 연구는 빌보드 차트에서 상위 30위와 하위 30위에 해당하는 곡을 이진 분류 문제로 정의하고, 가사 텍스트에 내재된 언어학적 신호를 활용한다. 데이터는 2001‑2010년 주간 차트에서 2,683곡을 수집했으며, 동일 곡이 여러 주에 등장하는 중복을 제거하고 각 곡의 최고 순위를 기준으로 라벨링하였다. 최종 분석 대상은 상위 30위와 하위 30위에 해당하는 1,622곡(상위 991곡, 하위 631곡)이다.
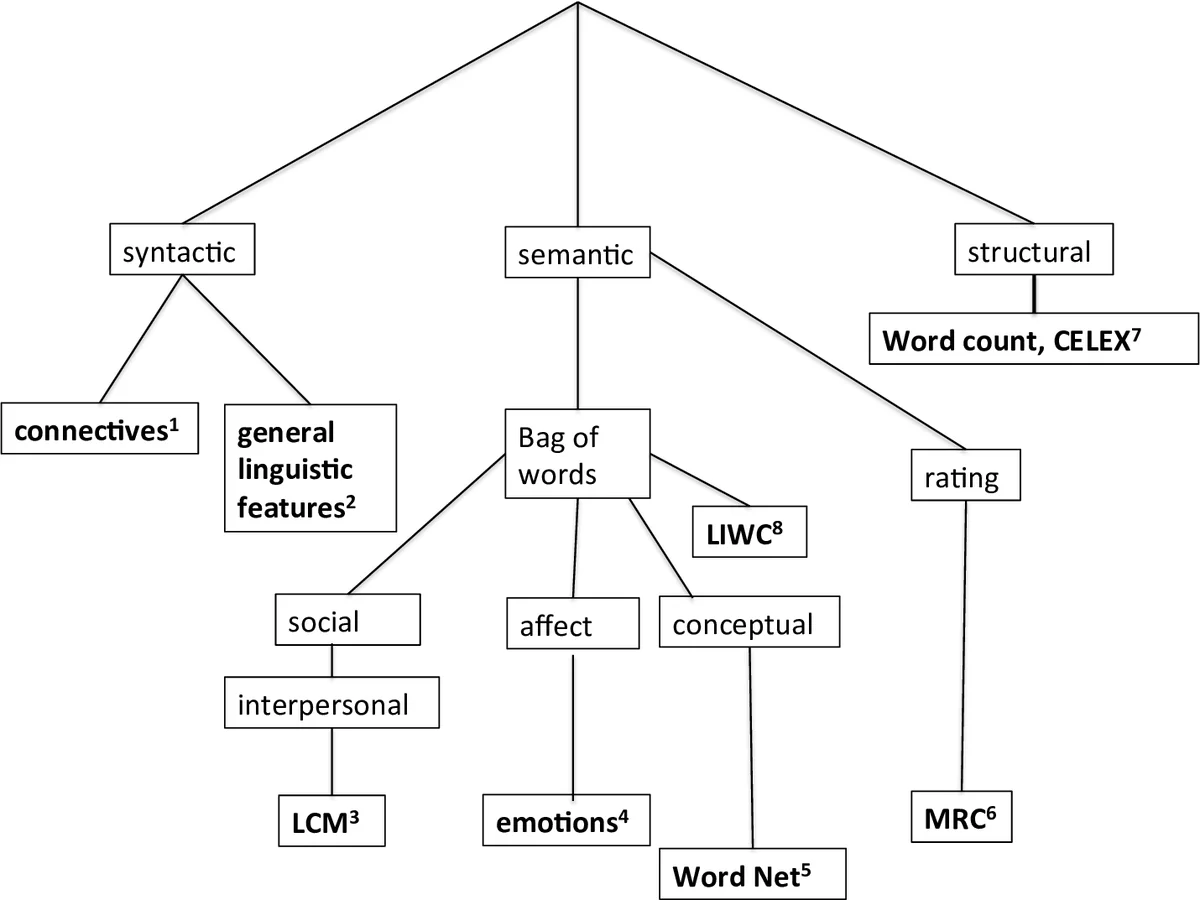
특징 추출 단계에서는 총 8개의 계산 언어학 알고리즘을 결합해 261개의 특성을 만든다. Biber(1991)의 67가지 문법·구문 지표, WordNet 기반 의미 카테고리(44개), Google 1‑gram 기반 빈도 분류, 언어적 상호작용을 포착하는 LCM, 감정 어휘 사전(Tausczik & Pennebaker), 연결어(긍정·부정·시간·인과) 파라미터, CELEX와 MRC 데이터베이스에서 얻은 어휘 빈도·친숙도·구체성·의미성 등을 포함한다. 이러한 풍부한 특성은 가사의 구조적, 의미적, 정서적 측면을 정량화한다.
특성 수가 많고 표본이 상대적으로 적은 상황에서 차원 축소가 필요했으며, 연구진은 주성분 분석(PCA)을 적용해 전체 분산의 60 %를 설명하는 39개의 주성분을 선택했다. PCA는 잡음을 감소시키고 모델 학습을 안정화하지만, 원래 특성의 해석 가능성을 희생한다는 단점이 있다.
클래스 불균형(상위:하위 ≈ 1.5:1)을 해결하기 위해 SMOTE 기법을 사용해 소수 클래스(하위 30위)를 합성 샘플로 보강하였다. 이후 10‑폴드 교차검증으로 세 종류의 SVM 커널(라디얼, 다항, 선형)을 평가했으며, 라디얼(지수) 커널이 정밀도·재현율 0.76, κ = 0.51로 가장 우수했다. 베이즈, 나이브 베이즈, 의사결정 트리 등 다른 분류기와 비교했을 때 성능 격차가 뚜렷했다.
결과 해석에서 κ = 0.51은 중간 수준의 합의력을 의미한다(0.41‑0.60은 ‘보통’ 수준). 따라서 모델이 무작위 추측(0.5)보다 현저히 나은 예측을 제공하지만, 아직 실용적인 수준에 도달하기 위해서는 추가적인 개선이 필요하다.
한계점으로는 (1) 가사만을 사용했기 때문에 멜로디·리듬· 프로덕션 등 청각적 요소를 배제했다는 점, (2) 데이터가 10년 구간의 미국 차트에 국한돼 있어 문화·시대적 편향이 존재한다는 점, (3) PCA 후 특성 해석이 어려워 어떤 언어적 요소가 히트에 기여했는지 구체적 인사이트를 제공하지 못한다는 점을 들 수 있다. 향후 연구에서는 오디오 피처와 결합한 멀티모달 모델, 시계열 기반의 연도별 트렌드 분석, 그리고 특성 선택 기법을 통한 해석 가능성 강화 등을 제안한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기