빅데이터 저장·처리 기술 종합 리뷰
초록
본 논문은 빅데이터 환경에서 데이터 저장과 조작을 지원하는 주요 알고리즘과 기술들을 체계적으로 정리한다. 분산 파일 시스템, NoSQL 데이터베이스, 컬럼형 스토어, 스트리밍 처리 프레임워크, 그래프 처리 엔진 등 각 기술의 핵심 원리와 장단점을 비교하고, 관련 논문 및 오픈소스 구현체를 참고문헌 형태로 제공한다.
상세 분석
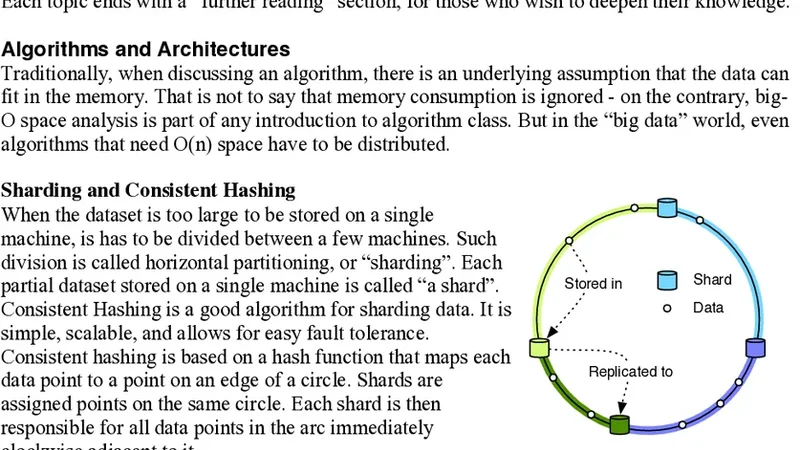
빅데이터 저장·처리 기술은 크게 영구 저장 계층과 실시간·배치 처리 계층으로 구분할 수 있다. 영구 저장 측면에서는 HDFS와 Ceph 같은 분산 파일 시스템이 기본 인프라를 제공한다. HDFS는 대용량 파일을 블록 단위로 복제하여 내결함성을 확보하고, 데이터 로컬리티를 활용해 MapReduce 작업의 I/O 효율을 높인다. 반면 Ceph는 객체 스토리지와 블록 스토리지를 통합해 높은 확장성과 유연성을 제공한다.
NoSQL 데이터베이스는 스키마가 고정되지 않은 워크로드에 적합한데, 키‑값 저장소인 Redis와 DynamoDB, 컬럼 패밀리 기반인 Cassandra와 HBase, 문서 지향인 MongoDB가 대표적이다. Cassandra는 라운드‑로빈 파티셔닝과 튜닝 가능한 일관성 모델을 통해 전 세계에 걸친 쓰기 확장성을 보장한다. HBase는 HDFS 위에 구축돼 대규모 스캔과 랜덤 읽기/쓰기에 강점이 있지만, 쓰기 지연이 상대적으로 크다.
컬럼형 스토어인 Parquet, ORC, Avro는 열 기반 압축과 인코딩을 활용해 분석 쿼리의 스캔 비용을 크게 절감한다. 특히 Parquet은 스키마 진화와 복합형 데이터 타입을 지원해 Spark, Hive, Presto와의 호환성이 뛰어나다.
배치 처리 프레임워크는 전통적인 MapReduce에서 Spark, Flink 등 메모리 중심 엔진으로 진화했다. Spark는 RDD와 DataFrame API를 통해 반복 연산을 최적화하고, Catalyst 옵티마이저가 쿼리 플랜을 자동 튜닝한다. Flink는 스트리밍‑배치 통합 모델을 제공해 정확히‑한 번 처리와 상태 관리가 핵심인 실시간 분석에 강점이 있다.
스트리밍 처리 영역에서는 Apache Kafka가 고성능 로그 수집·전달 파이프라인으로 자리 잡았으며, Kafka Streams와 ksqlDB는 스트림 프로세싱을 선언적 DSL로 구현한다. Apache Storm과 Samza는 저지연 이벤트 처리에 특화돼 있지만, 운영 복잡도가 상대적으로 높다.
그래프 처리 기술로는 Pregel‑style 시스템인 Apache Giraph와 실시간 그래프 데이터베이스인 Neo4j, JanusGraph이 있다. Giraph는 대규모 정적 그래프 분석에 효율적이며, Neo4j는 ACID 트랜잭션과 Cypher 쿼리 언어를 통해 복잡한 관계 탐색을 지원한다.
마지막으로 클라우드 네이티브 스토리지와 데이터 레이크가 부상하고 있다. AWS S3, Azure Data Lake Storage, Google Cloud Storage는 무제한 확장성을 제공하며, Iceberg와 Delta Lake 같은 테이블 포맷은 스냅샷 관리와 ACID 트랜잭션을 구현한다. 이러한 기술 스택은 데이터 파이프라인 전반에 걸쳐 선택과 조합이 가능하도록 설계돼 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기