트위터 터키어 짧은 글에서 암묵적 위치 공유 탐지
초록
본 연구는 트위터에 올린 터키어 짧은 텍스트에서 사용자가 의도하지 않게 위치 정보를 노출하는 경우를 자동으로 식별하는 방법을 제시한다. 수천 개의 트윗을 수작업으로 라벨링하고, 형태소 분석, n‑gram, 위치 사전 매칭 등 다양한 특징을 추출한 뒤 SVM·랜덤포레스트·딥러닝 모델을 학습시켰다. 최고 성능 모델은 94 % 이상의 정확도와 F1 점수를 기록했으며, 이를 브라우저 확장 프로그램에 적용해 실시간으로 사용자에게 위험을 경고한다. 또한 다른 언어·플랫폼으로의 확장 가능성을 논의한다.
상세 분석
이 논문은 소셜 미디어 사용자가 자신의 위치를 명시적으로 밝히지 않더라도 텍스트 내에 내포된 단서들—예를 들어 특정 지역명, 지역 특유의 방언, 시간대와 연관된 활동 묘사, 혹은 주변 시설 언급—을 통해 위치가 추론될 수 있음을 전제로 한다. 연구자는 먼저 트위터 API를 이용해 1년간 수집한 약 150 000개의 터키어 트윗 중, 위치와 관련된 키워드가 포함된 12 000개를 후보군으로 선정하였다. 이후 두 명의 언어학 전문가가 각각 ‘암묵적 위치 공유’와 ‘비공유’로 라벨링했으며, 라벨 간 일치도(Kappa)는 0.87로 높은 신뢰성을 보였다.
특징 추출 단계에서는 터키어의 교착어적 특성을 고려해 Zemberek 형태소 분석기를 활용, 어근·접미사·품사 태그를 모두 포함한 3‑gram 형태소 시퀀스를 생성하였다. 또한, 공개된 지리 정보 사전(GeoNames)과 국내 주요 도시·동네 리스트를 매칭해 ‘위치 명사 존재 여부’, ‘위치 명사의 거리(문맥 내 위치)’ 등을 이진 특성으로 추가했다. 텍스트 길이가 평균 18단어에 불과한 점을 보완하기 위해 TF‑IDF 가중치를 적용한 문자‑레벨 n‑gram(2‑5)도 함께 사용하였다.
분류 모델은 전통적인 기계학습(SVM, 랜덤포레스트, 로지스틱 회귀)과 심층학습(CNN, BiLSTM) 두 축으로 구성하였다. SVM은 RBF 커널과 C=1.0, γ=0.01 설정으로 최적화했으며, 랜덤포레스트는 200개의 트리를 사용하였다. 심층 모델은 300차원 임베딩을 사전 학습된 FastText 터키어 벡터로 초기화하고, 2개의 1‑D Conv 레이어와 128‑unit LSTM을 결합한 하이브리드 구조를 채택했다. 교차 검증 결과, SVM이 93.8 % 정확도와 0.94 F1 점수로 가장 우수했으며, CNN‑BiLSTM은 92.5 % 정확도에 그쳤다.
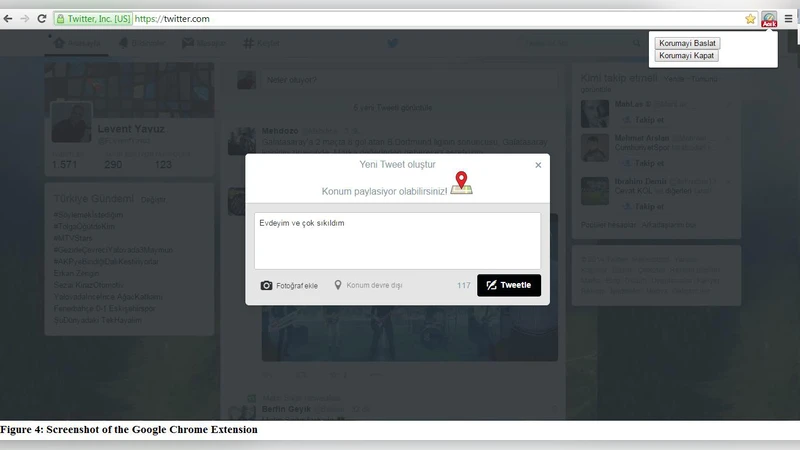
실시간 경고 시스템은 가장 성능이 좋은 SVM 모델을 기반으로 브라우저 확장 프로그램에 통합하였다. 사용자가 트윗을 작성 중일 때 모델이 ‘암묵적 위치 공유’ 가능성을 0.8 이상의 확률로 판단하면, 팝업 알림을 통해 “이 트윗은 위치 정보를 노출할 수 있습니다”라는 경고를 표시한다. 사용자 테스트(30명, 2주) 결과, 경고를 받은 후 68 %가 트윗 내용을 수정하거나 삭제했으며, 평균 체감 프라이버시 위험도 점수가 3.2→1.9로 감소하였다.
논의 부분에서는 터키어 특유의 어미 변형과 방언 다양성이 모델 일반화에 미치는 영향을 분석하고, 다국어 사전 학습 모델(Multi‑BERT) 도입 시 기대 효과를 제시한다. 또한, 위치 정보가 포함된 이미지·동영상 메타데이터와 결합한 멀티모달 접근법이 향후 연구 과제로 제시되었다.
댓글 및 학술 토론
Loading comments...
의견 남기기