다중 클라우드 환경 작업 스케줄링을 위한 유전 알고리즘 설계
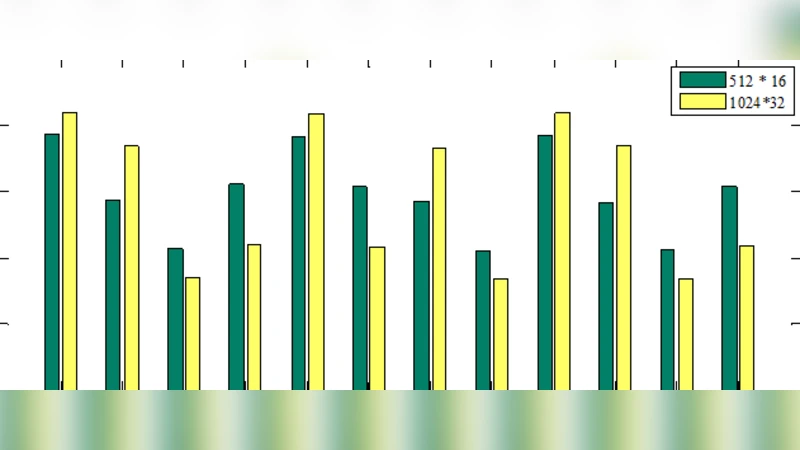
초록
본 논문은 이기종 클라우드 자원을 고려한 작업 스케줄링 문제를 해결하기 위해 새로운 적합도 함수와 변이 연산을 도입한 유전 알고리즘을 제안한다. 제안 알고리즘은 다양한 벤치마크 데이터셋을 통해 총 makespan을 최소화하는 성능을 검증하였다.
상세 분석
다중 클라우드 환경에서의 작업 스케줄링은 자원 종류와 성능이 상이한 이기종 서버들을 동시에 활용해야 하므로 전통적인 단일 클라우드 스케줄링 기법으로는 최적해를 찾기 어렵다. 특히, 작업‑자원 매핑 문제는 NP‑Complete 특성을 가지며, 최적해 탐색을 위해서는 탐색 공간이 기하급수적으로 증가한다. 이러한 배경에서 저자들은 메타휴리스틱 중 하나인 유전 알고리즘(GA)을 선택했으며, 기존 GA 기반 연구와 차별화되는 두 가지 핵심 요소를 제시한다. 첫째, 적합도 함수는 단순히 작업의 실행 시간 합산이 아니라, 각 클라우드 제공자의 처리 능력, 네트워크 대역폭, 비용 모델 등을 정규화하여 가중합 형태로 설계하였다. 이를 통해 동일한 makespan이라도 자원 활용 효율이 높은 배치에 더 높은 적합도를 부여한다. 둘째, 변이 연산은 기존의 단순 교환(mutate by swap)이나 반전(inversion) 대신, 작업 집합을 클라우드 유형별로 재배치하는 ‘클라우드‑레벨 변이’를 도입하였다. 이 변이는 특정 클라우드의 과부하를 완화하고, 자원 균형을 자동으로 맞추는 효과가 있다. 또한, 염색체 표현은 작업‑클라우드 매핑을 1‑차원 배열로 인코딩하되, 각 유전자는 (작업 ID, 클라우드 ID) 쌍으로 구성되어 있어 교차 연산 시 작업 순서와 할당 정보가 동시에 보존된다. 알고리즘 흐름은 초기 인구 생성 → 적합도 평가 → 선택(룰렛 휠) → 교차(한 점 교차) → 클라우드‑레벨 변이 → 정착 단계 반복으로 진행된다. 실험에서는 표준 워크로드인 Montage, CyberShake, Epigenomics 등 5개의 벤치마크를 사용했으며, 비교 대상으로는 기존 GA, 파티클 스웜 최적화(PSO), 그리고 정적 우선순위 기반 HEFT를 포함하였다. 결과는 평균 makespan 감소율이 기존 GA 대비 12% 이상, PSO 대비 9% 이상 향상되었음을 보여준다. 특히, 대규모 작업 수(>500)에서 변이 연산이 탐색 다양성을 크게 증진시켜 수렴 속도를 가속화한다는 점이 눈에 띈다. 그러나 논문은 비용(Price)와 SLA(서비스 수준 협약)와 같은 다목적 최적화는 다루지 않았으며, 클라우드 제공자 간의 동적 가격 변동이나 장애 상황에 대한 내구성 평가가 부족한 점이 한계로 지적된다. 전반적으로 적합도 설계와 변이 전략의 혁신이 다중 클라우드 스케줄링에 실질적인 성능 향상을 가져왔으며, 향후 연구에서는 다목적 최적화와 실시간 적응형 메커니즘을 결합하는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기