차이 목표 전파: 비미분 신경망을 위한 새로운 학습 방법
초록
본 논문은 역전파의 미분 기반 한계를 극복하고자, 각 층에 목표값(target)을 전파하는 “목표 전파” 방식을 제안한다. 자동 인코더를 이용해 역방향 매핑을 학습하고, 불완전한 역매핑을 선형 보정하는 차이 목표 전파(difference target propagation)를 도입해 안정적인 학습을 구현한다. 실험 결과, 연속·이산·확률적 유닛을 포함한 깊은 네트워크에서 역전파와 동등하거나 그 이상 성능을 달성한다.
상세 분석
이 논문은 딥러닝에서 가장 널리 쓰이는 역전파(back‑propagation)가 미분값에 의존한다는 근본적인 제약을 지적한다. 특히 매우 깊고 비선형이 강한 네트워크, 혹은 파라미터와 손실 사이의 관계가 이산적인 경우(예: 비트 기반 스파이크 신경망)에서는 기울기가 소실·폭발하거나 0·∞가 되어 학습이 불가능해진다. 이러한 문제를 해결하기 위해 저자들은 “목표 전파(target propagation)”라는 새로운 신용 할당 메커니즘을 제안한다. 핵심 아이디어는 각 층의 활성값 hᵢ에 대해 목표값 ĥᵢ를 정의하고, 이 목표값을 역방향으로 전파해 각 층이 자체적인 로컬 손실 Lᵢ(ĥᵢ, hᵢ)를 최소화하도록 하는 것이다.
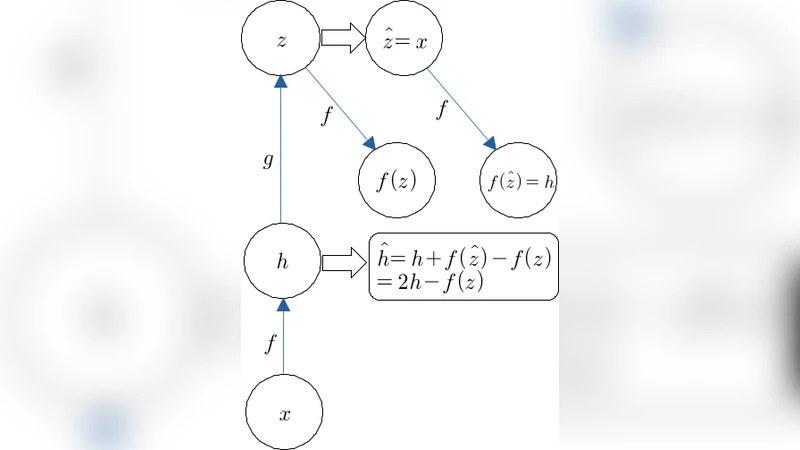
목표값을 구하는 방법으로는 각 전방 매핑 fᵢ에 대한 근사 역매핑 gᵢ를 학습한다. gᵢ는 자동 인코더 구조를 갖으며, fᵢ∘gᵢ≈I, gᵢ∘fᵢ≈I 를 만족하도록 훈련된다. 그러나 실제 자동 인코더는 완전한 역변환을 제공하지 못하고, 이로 인해 목표값을 단순히 ĥᵢ₋₁=gᵢ(ĥᵢ) 로 정의하면 최적화가 불안정해진다. 이를 보완하기 위해 논문은 “차이 목표 전파”라는 선형 보정식을 도입한다:
ĥᵢ₋₁ = hᵢ₋₁ + gᵢ(ĥᵢ) – gᵢ(hᵢ)
이 식은 gᵢ가 완전한 역함수가 아닐 때도 hᵢ가 목표값에 가까워지면 ĥᵢ₋₁도 자동으로 목표값에 가까워지도록 보장한다. 즉, hᵢ = ĥᵢ ⇒ ĥᵢ₋₁ = hᵢ₋₁ 라는 안정성 조건을 만족한다. 저자들은 이 조건이 학습 수렴을 촉진하고, 전역 손실 L이 감소하도록 하는 충분조건임을 정리와 정리를 통해 증명한다.
알고리즘 1은 전체 학습 흐름을 명시한다. ① 전방 패스로 모든 층의 활성값을 계산하고, ② 최상위 층에 대해 손실 기울기에 기반한 목표값을 만든다(ĥ_M = h_M – η∂L/∂h_M). ③ 차이 목표 전파 식을 이용해 하위 층들의 목표값을 순차적으로 구한다. ④ 각 gᵢ는 노이즈가 섞인 입력에 대한 재구성 손실 L_invᵢ 로 업데이트되고, ⑤ 각 fᵢ는 로컬 손실 Lᵢ = ‖fᵢ(hᵢ₋₁) – ĥᵢ‖² 로 업데이트된다. 최상위 층은 기존 손실 L을 직접 최소화한다.
이 접근법은 (1) 연속 실수값 유닛, (2) 이산 비트 유닛, (3) 확률적(스파이크) 유닛을 모두 다룰 수 있다는 점에서 기존 역전파와 차별화된다. 특히 이산·확률적 경우, 미분이 정의되지 않음에도 목표값 전파만으로 학습이 가능해진다. 실험에서는 MNIST, CIFAR‑10 등 표준 이미지 데이터와, 이산·확률적 네트워크 구조에 대해 RMSprop 기반 역전파와 비교했을 때 동등하거나 더 나은 정확도를 기록했다. 특히 확률적 네트워크에서는 기존 최첨단 결과를 능가하였다.
이 논문은 신경망 학습에 있어 “기울기” 대신 “목표”라는 새로운 신용 할당 패러다임을 제시함으로써, 미분 불가능한 하드웨어(예: 디지털 비트 회로)나 생물학적 신경 메커니즘을 보다 현실적으로 모델링할 수 있는 길을 열었다. 향후 연구에서는 목표값 생성 과정의 효율화, 비대칭 피드백 가중치 학습, 그리고 시계열·강화학습 환경에의 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기