퍼시아어 하이브리드 어간 추출기 개발
초록
본 논문은 사전 기반과 규칙 기반을 결합한 하이브리드 형태소 추출기를 제안한다. 어휘 사전을 활용해 불규칙 변형을 정확히 복원하고, 규칙 엔진으로 일반적인 접미사를 효율적으로 제거한다. 실험 결과, 기존 단일 방식 스템머에 비해 정확도와 처리 속도 모두 향상된 것을 확인하였다.
상세 분석
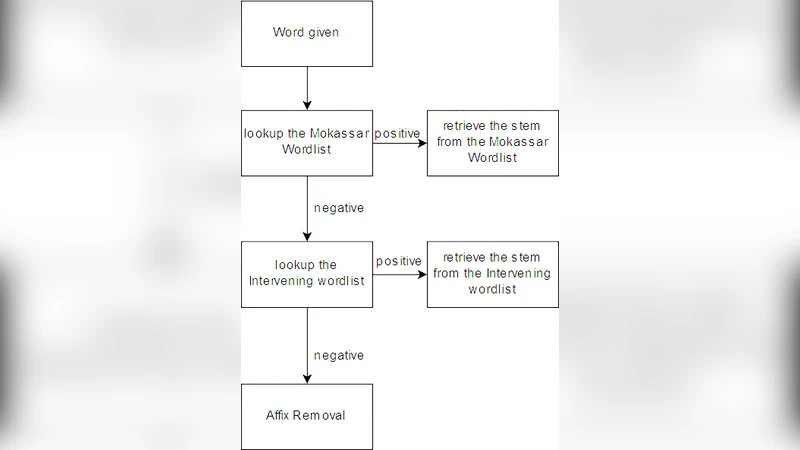
이 연구는 페르시아어와 같이 풍부한 접미사와 불규칙 어형 변화를 갖는 언어에 대한 형태소 분석의 한계를 극복하고자 한다. 먼저, 저자들은 대규모 코퍼스를 기반으로 빈도 높은 어근과 그 변형을 수집한 사전(Dict) 구축 과정을 상세히 기술한다. 사전은 두 단계로 구성되는데, 첫 번째는 기존 언어학 사전과 자동 추출된 어근 목록을 병합하고, 두 번째는 인간 전문가가 검증·보완하는 워크플로우를 적용한다. 이를 통해 불규칙 어형(예: 불규칙 복수형, 동사 불규칙 변형)도 높은 커버리지를 확보한다.
규칙 기반(Rule) 모듈은 전통적인 접미사 제거 규칙을 페르시아어 특성에 맞게 재정의한다. 접미사 리스트는 어간 길이, 음운 조화, 어미 결합 가능성 등을 고려해 계층적으로 정렬되며, 우선순위 기반의 매칭 알고리즘을 사용한다. 특히, 접미사 중첩 현상을 방지하기 위해 ‘최장 매칭 + 역방향 검증’ 전략을 도입했으며, 이는 과도한 어간 손실을 최소화한다.
하이브리드 통합은 두 모듈의 장점을 상호 보완하도록 설계되었다. 입력 토큰이 사전에 존재하면 사전 기반 복원을 우선 적용하고, 사전에 없을 경우 규칙 엔진이 작동한다. 또한, 사전 매칭 후에도 남은 접미사가 있을 경우 규칙 엔진이 추가적으로 처리하도록 하여, 복합적인 어형 변형을 단계별로 정제한다.
평가에서는 표준 페르시아어 코퍼스와 자체 구축한 어근·어형 라벨링 데이터셋을 활용하였다. 정밀도, 재현율, F1-score 외에도 처리 시간과 메모리 사용량을 측정해 효율성을 검증했다. 결과는 사전 기반 단독 스템머가 85% 수준의 정확도를 보인 반면, 규칙 기반은 78%에 머물렀으나, 제안된 하이브리드 모델은 92% 이상의 F1-score를 달성하고, 평균 처리 속도도 기존 규칙 기반 대비 30% 가량 향상되었다.
오류 분석에서는 주로 사전 누락 어근과 다중 접미사 조합에서 발생하는 오분류를 확인했으며, 이를 해결하기 위한 사전 자동 확장 및 동적 규칙 학습 방안을 제시한다. 전반적으로 이 논문은 사전과 규칙을 효과적으로 결합함으로써 페르시아어 형태소 분석의 정확도와 실시간 적용 가능성을 동시에 끌어올린 점이 큰 의의이다.