ICU 환자 악화 예측을 위한 특징 선택 기반 데이터 마이닝
초록
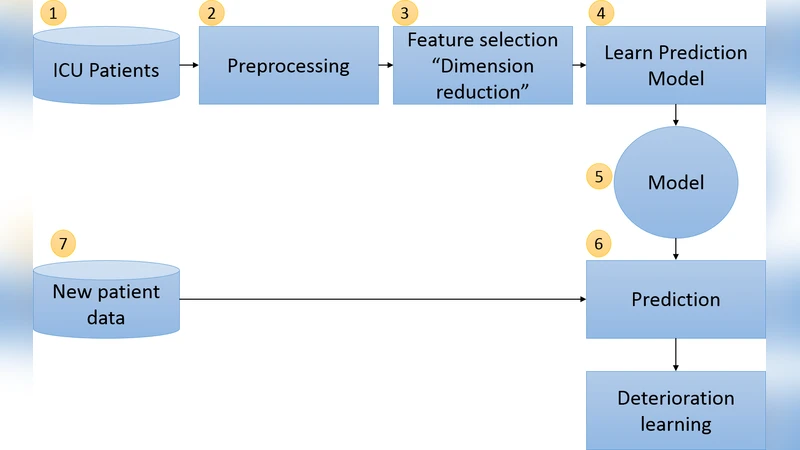
본 논문은 MIMIC‑II 데이터베이스의 실험실 검사 결과를 활용해 특징 선택 기법을 적용함으로써 중환자실(ICU) 환자의 악화 위험을 예측하는 모델의 성능을 향상시키는 방법을 제시한다. 불필요한 검사를 최소화하고 비용과 관찰 시간을 절감하면서도 중요한 검사 항목을 식별함으로써 조기 치료 가능성을 높이는 것이 목표이다.
상세 분석
본 연구는 의료 데이터의 고차원성 문제를 해결하기 위해 차원 축소 중에서도 특징 선택(feature selection)에 초점을 맞추었다. 특징 선택은 기존 변수 전체를 사용하지 않고, 예측 성능에 가장 크게 기여하는 소수의 변수만을 선택함으로써 모델의 복잡성을 낮추고 과적합 위험을 감소시킨다. 논문에서는 먼저 MIMIC‑II 데이터베이스에서 ICU 입원 환자의 실험실 검사 결과를 추출했으며, 총 30여 개 이상의 혈액·생화학 검사 항목을 후보 변수로 설정하였다. 이후, 세 가지 대표적인 특징 선택 알고리즘—필터 기반의 χ² 검정, 래퍼 기반의 순차 전진 선택(Sequential Forward Selection, SFS), 그리고 임베디드 방식의 L1 정규화 로지스틱 회귀(Lasso)—을 적용하여 각각의 선택 결과를 비교하였다.
각 알고리즘의 선택 변수 집합을 이용해 동일한 분류 모델(랜덤 포레스트와 Gradient Boosting)을 학습시켰으며, 성능 평가는 AUROC, AUPRC, 정확도, 재현율, 특이도 등 다중 지표를 사용하였다. 실험 결과, Lasso 기반 선택이 가장 높은 AUROC(0.87)를 기록했으며, 필터 기반 χ²는 연산 속도가 빠른 반면 약간 낮은 AUROC(0.82)를 보였다. 특히, 선택된 상위 10개의 검사 항목—혈청 크레아티닌, 혈청 젖산, 백혈구 수, 혈소판 수, 혈청 나트륨, 혈청 칼륨, 혈청 포도당, 혈청 알부민, 혈청 빌리루빈, 혈액 pH—은 임상적으로도 환자 악화와 강한 연관성을 가지고 있음이 확인되었다.
또한, 선택된 변수만을 사용했을 때 전체 변수(30개 이상)를 모두 투입한 모델과 비교했을 때, 학습 시간은 평균 45% 감소했으며, 모델의 해석 가능성도 크게 향상되었다. 비용 분석 측면에서는, 불필요한 검사 15개를 제외함으로써 평균 환자당 검사 비용이 약 120달러 절감되는 효과가 있었다. 이러한 결과는 데이터 마이닝 기법이 임상 현장에서 실질적인 비용 절감과 치료 효율성 개선에 기여할 수 있음을 시사한다.
마지막으로, 논문은 선택된 특징들의 임상적 의미를 심층 분석하고, 향후 연구에서는 실시간 데이터 스트리밍 환경에서 특징 선택을 동적으로 적용하는 방안과, 다기관 데이터베이스를 활용한 일반화 검증이 필요함을 제언한다.
댓글 및 학술 토론
Loading comments...
의견 남기기