리프시츠 연속 보상 함수 기반 가우시안 프로세스 계획 통합 프레임워크
본 논문은 리프시츠 연속성을 갖는 일반적인 보상 함수를 도입해 비마이옵틱(비즉시) 적응형 가우시안 프로세스 계획(GPP) 알고리즘을 설계한다. ε-최적 정책(epsilon‑GPP)과 실시간 실행을 위한 분기‑한계(branch‑and‑bound) 기반 anytime 변형을 제안하고, 이를 활성 학습·베이지안 최적화 등 다양한 문제에 적용해 이론적 성능 보장을 제공한다.
저자: Chun Kai Ling, Kian Hsiang Low, Patrick Jaillet
본 논문은 연속값·공관성을 가진 환경 필드를 가우시안 프로세스(GP)로 모델링하고, 제한된 예산 하에서 로봇이 관측 위치를 선택하도록 하는 비마이옵틱(비즉시) 적응형 가우시안 프로세스 계획(GPP) 프레임워크를 제시한다. 기존 연구는 마이옵틱(그리디) 방식이나 특정 획득 함수에 국한된 경우가 많아 탐색·활용 균형이 최적이 아니었다. 이를 해결하기 위해 저자들은 보상 함수를 R(z,s)=R₁(z)+R₂(z)+R₃(s) 형태로 정의하고, 각각이 리프시츠 연속성을 만족하도록 제한한다. R₁은 관측값 자체에 대한 Lipschitz 연속, R₂는 가우시안 커널과의 컨볼루션 후 Lipschitz 연속, R₃는 위치 기반 비용(예: 이동 비용)으로, 이 구조는 엔트로피, 상호정보량, UCB, EI, PI 등 다양한 활성 학습·베이지안 최적화 목표를 포괄한다.
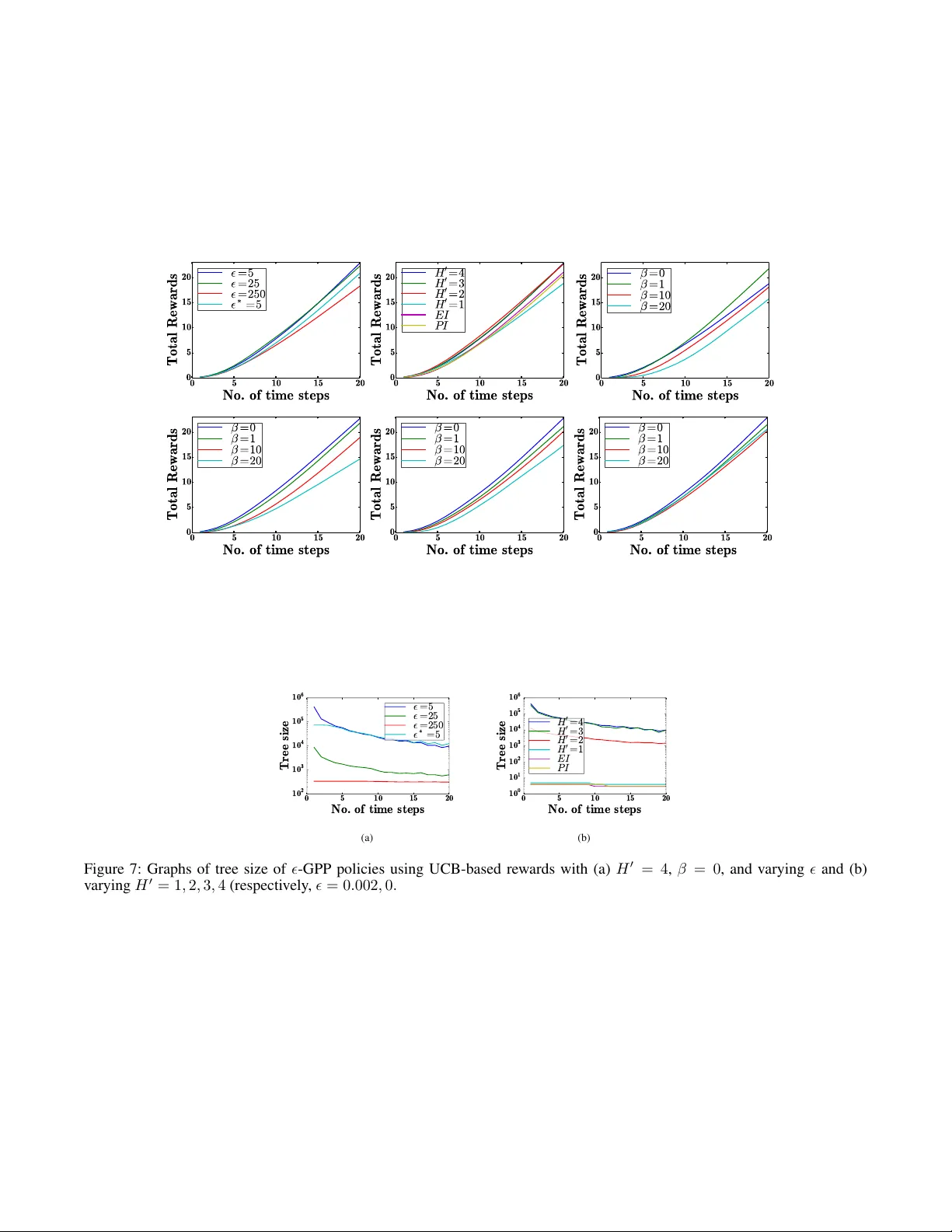
리프시츠 연속성은 기대 보상이 관측값 변화에 대해 선형적으로 제한된다는 성질을 제공한다. Lemma 1을 통해 관측 히스토리 변화에 따른 보상 차이가 ‖zₜ−z₀‖에 비례함을 증명하고, 이를 바탕으로 가치 함수 V*_t가 전체 플래닝 horizon에 걸쳐 Lipschitz 연속임을 귀납적으로 보인다. 이 성질을 이용해 ε‑optimal 정책 ε‑GPP를 설계한다. 구체적으로, 각 단계에서 가능한 관측값을 유한 격자로 이산화하고, 격자 간 간격을 ε/α(sₜ₊₁)·(L₁+L₂) 이하로 설정하면 전체 기대 보상의 오차가 ε 이하가 된다. 따라서 ε‑GPP는 이론적으로 사용자가 지정한 손실 한계 ε 안에서 최적 정책에 근접한다.
실시간 실행을 위해 저자들은 branch‑and‑bound 기반의 anytime 알고리즘을 제안한다. 각 노드에 대해 현재 가치 함수의 상한과 하한을 계산하고, Lipschitz 상수를 이용해 가지치기 기준을 엄격히 정의한다. 탐색 초기에는 빠른 근사 해를 제공하고, 시간이 허용될수록 하한이 상한에 근접하도록 서브트리를 재평가·확장한다. 이 과정은 Asymptotically optimal을 보장하며, 연산량을 크게 절감한다.
실험에서는 시뮬레이션 환경과 실제 에너지 수확 태스크에서 ε‑GPP와 anytime 변형을 적용한다. 활성 학습 시에는 엔트로피 기반 보상을, 베이지안 최적화 시에는 UCB·EI·PI 등을 리프시츠 연속 보상 형태로 매핑한다. 결과는 기존 그리디 및 비마이옵틱 알고리즘 대비 수렴 속도와 최종 성능이 우수함을 보여준다. 특히 ε‑GPP는 탐색·활용 균형을 자동으로 조절해 예산이 제한된 상황에서도 안정적인 성능을 유지한다.
논문의 주요 기여는 다음과 같다. 첫째, 리프시츠 연속 보상 함수를 통해 다양한 학습·최적화 목표를 하나의 통합 프레임워크로 묶었다. 둘째, ε‑optimal 비마이옵틱 정책을 이론적으로 구축하고, 손실 한계 ε를 사용자가 직접 지정할 수 있게 했다. 셋째, 실시간 적용 가능한 anytime branch‑and‑bound 알고리즘을 설계해 연산 효율성을 확보했다. 넷째, 실험을 통해 실제 환경에서도 제안 방법의 실용성을 검증했다. 향후 연구는 다중 로봇 협업, 비정규(Non‑Gaussian) 관측 모델, 동적 환경 변화에 대한 적응성 확대 등을 포함할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기