딥 예측 모델을 활용한 강화학습 탐색 보너스
본 논문은 Atari와 같은 고차원 이미지 입력을 갖는 강화학습 환경에서, 신경망 기반의 상태 인코더와 동적 모델을 학습해 예측 오차를 탐색 보너스로 활용한다. 예측 오차가 큰 상태를 ‘새로운’ 상태로 간주해 보상에 보너스를 추가함으로써, 기존 ε‑greedy, Boltzmann, Thompson sampling보다 학습 속도와 최종 성능을 크게 향상시킨다. 또한 학습 진행을 평가하기 위한 AUC‑100 지표를 제안한다.
저자: Bradly C. Stadie, Sergey Levine, Pieter Abbeel
**1. 서론**
강화학습에서 탐색‑활용 트레이드오프는 에이전트가 최적 정책을 찾는 데 핵심적인 문제이다. 기존 PAC‑MDP, 베이지안 탐색 보너스(BEB) 등은 이론적 보장을 제공하지만, 상태‑행동 공간을 명시적으로 열거해야 하는 한계 때문에 고차원 이미지 입력을 다루는 Atari와 같은 도메인에서는 실용적이지 않다. 따라서 대부분의 대규모 RL 연구는 ε‑greedy 같은 단순 휴리스틱에 의존한다. 저자는 이러한 한계를 극복하고자, 모델 기반 탐색 보너스를 딥 뉴럴 네트워크와 결합한 새로운 방법을 제안한다.
**2. 사전 지식**
MDP 정의와 탐색 보너스의 일반 형태 R_bonus = R + β·N(s,a) 를 소개한다. 기존 방법은 N(s,a)를 방문 횟수 기반으로 정의했지만, 고차원 연속 공간에서는 카운팅이 불가능하므로 함수 근사와 표현 학습이 필요함을 강조한다.
**3. 모델 기반 탐색 보너스 설계**
- **상태 인코더 σ**: 8계층 자동인코더를 훈련해 원시 픽셀을 128 차원 저차원 표현으로 압축한다. 특히 6번째 은닉층 출력을 인코딩으로 사용해, 압축과 재구성 사이의 균형을 맞춘다. 두 가지 학습 방식(Static AE, Dynamic AE)을 실험했으며, 둘 다 충분히 의미 있는 특징을 학습한다.
- **동적 모델 M_φ**: 인코딩 σ(s)와 행동 a를 입력으로 받아 다음 인코딩 σ(s′)를 예측하는 2계층 신경망이다. 손실은 유클리드 거리이며, 초기에는 거의 항등 함수에 가까운 예측을 보이다가 학습이 진행될수록 복잡한 전이 패턴을 포착한다.
- **탐색 보너스 계산**: 예측 오차 e(s,a)=‖σ(s′)−M_φ(σ(s),a)‖² 를 현재까지 관측된 최대 오차 max e 로 정규화하고, 시간 가중치 t·C 를 곱해 N(s,a)=\(\bar e\)·t·C 로 정의한다. β는 보너스 강도를 조절한다.
**4. 알고리즘**
Algorithm 1은 온라인 RL 루프에 위 과정을 삽입한다. 매 스텝마다 (s,a,s′,R) 튜플을 저장하고, 보너스를 계산해 정책 업데이트에 사용한다. 일정 에포크마다 메모리 버퍼를 활용해 M_φ 를 재학습하고, 필요 시 σ 도 재학습한다. 이 구조는 DQN, Actor‑Critic 등 다양한 RL 알고리즘에 모듈식으로 적용 가능하다.
**5. 딥 아키텍처 구현**
- **자동인코더**: 8계층, 중간 압축 차원 128, ReLU 활성화, Euclidean loss.
- **동적 모델**: 입력 차원 = 인코딩 차원 + 행동 원-핫, 출력 차원 = 인코딩 차원, 두 개의 완전 연결 층, L2 손실.
- **학습 세부사항**: 자동인코더는 250k 이미지로 사전 학습 후 25k 이미지로 검증. 동적 모델은 50000 스텝마다 업데이트, β와 C는 실험적으로 튜닝.
**6. 실험**
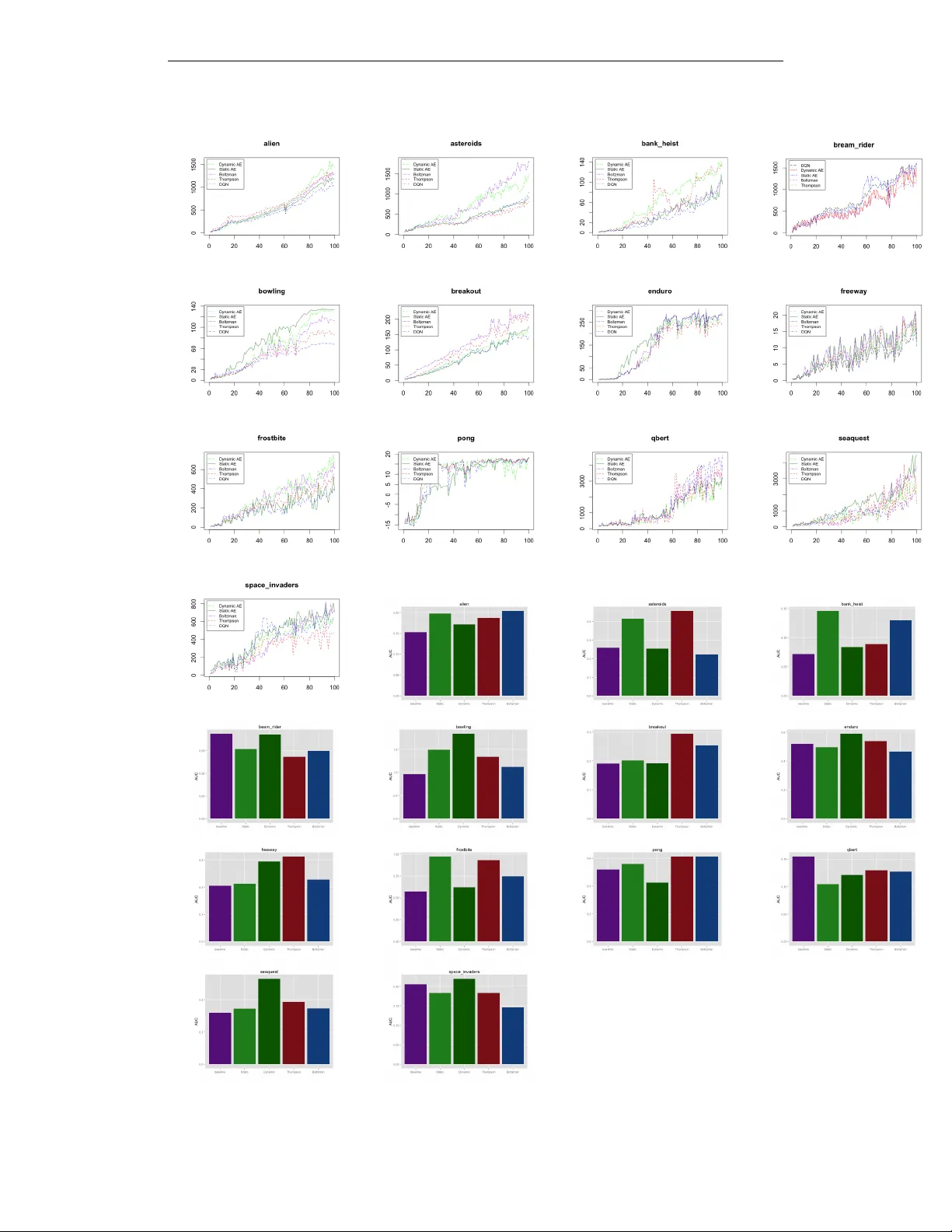
Atari 2600 게임 30여 종을 대상으로 DQN 기반 에이전트에 탐색 보너스를 적용했다. 비교 대상은 ε‑greedy, Boltzmann, Thompson sampling이다. 평가 지표는 (1) 최종 점수, (2) AUC‑100 (첫 100만 프레임까지의 평균 점수). 결과는 대부분의 게임에서 모델 기반 보너스가 학습 곡선을 급격히 앞당기고, 최종 점수와 AUC‑100 모두 크게 상승함을 보여준다. 특히 인간 수준을 크게 초과하던 ‘Montezuma’s Revenge’, ‘Private Eye’ 등에서는 기존 방법이 거의 학습되지 못했으나, 제안 방법은 의미 있는 진행을 보였다.
**7. 관련 연구와 차별점**
전통적인 R‑MAX, E³ 등은 상태 카운팅에 의존해 고차원 연속 공간에 적용이 어려웠다. 최근 curiosity‑driven 탐색(예: Intrinsic Curiosity Module)도 모델 예측 오차를 활용하지만, 대부분 행동‑조건부 예측을 직접 픽셀 수준에서 수행한다. 본 논문은 자동인코더를 통해 의미 있는 특징을 추출하고, 저차원 공간에서 예측 오차를 계산함으로써 효율성을 크게 개선한다. 또한 제안된 AUC‑100 지표는 학습 속도를 정량화하는 새로운 방법이다.
**8. 한계 및 향후 연구**
- 추가적인 연산 비용: 인코더와 동적 모델 학습이 별도 GPU 자원을 요구한다.
- 파라미터 민감도: β와 C 값이 환경마다 최적화 필요.
- 모델 표현력: 현재는 간단한 2계층 MLP이므로, 복잡한 물리 법칙이나 장기 의존성을 포착하기엔 한계가 있다. 향후 변분 오토인코더, 베이지안 신경망, 혹은 시계열 모델(LSTM, Transformer) 등을 도입해 불확실성을 직접 추정하고 보너스에 반영하는 연구가 기대된다.
**9. 결론**
본 논문은 딥 뉴럴 네트워크 기반 상태 인코더와 동적 모델을 이용해 예측 오차를 탐색 보너스로 전환함으로써, 고차원 이미지 입력을 갖는 강화학습 환경에서 탐색 효율성을 크게 향상시켰다. 제안된 방법은 기존 탐색 휴리스틱보다 일관된 성능 개선을 보이며, 모듈식 설계 덕분에 다양한 RL 알고리즘에 쉽게 통합될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기