재귀 강화학습 하이브리드 접근법
초록
부분관측 CRM 문제에서 RNN/LSTM 기반의 상태표현을 슈퍼바이즈드 학습으로 학습하고, 이를 DQN에 연결해 장기 보상을 최적화하는 하이브리드 모델을 제안한다. 직접 메일링 데이터셋을 이용한 실험에서 기존 선형 Q‑함수와 순수 DQN보다 우수한 성능을 보였다.
상세 분석
본 논문은 부분관측 마코프 의사결정 과정(POMDP)에서 숨겨진 상태를 명시적으로 설계하는 전통적 방법의 한계를 지적하고, 데이터‑드리븐 방식으로 상태표현을 자동 학습하는 새로운 프레임워크를 제시한다. 핵심 아이디어는 두 개의 신경망을 결합하는 하이브리드 구조이다. 첫 번째 네트워크는 RNN 또는 LSTM 형태의 순환 신경망으로, 관측 oₜ와 즉시 보상 rₜ, 다음 관측 oₜ₊₁을 예측하는 슈퍼바이즈드 학습 목표를 갖는다. 이 과정에서 은닉 상태 ĥₜ는 과거 상호작용 전체를 압축한 잠재 표현으로 학습되며, 장기 의존성을 효과적으로 포착한다. 두 번째 네트워크는 전통적인 Deep Q‑Network(DQN)이며, 입력으로 앞 단계에서 얻은 은닉 상태 ĥₜ를 사용한다. DQN은 Q‑함수 Q(s,a;θ) 를 근사하고, ε‑greedy 정책을 통해 행동 aₜ를 선택한다.
학습 절차는 매 SGD 반복마다 두 단계가 교차한다. 먼저, 순환 네트워크는 관측‑보상 쌍을 이용해 예측 손실을 최소화한다(예: 평균제곱오차). 그 다음, 고정된 은닉 상태를 DQN에 공급하여 Q‑러닝 업데이트를 수행한다. 이때 Q‑러닝의 TD‑오차는 DQN 파라미터뿐 아니라 은닉 상태를 생성하는 RNN 파라미터에도 역전파되어, 장기 보상 최적화와 상태표현 학습이 공동으로 이루어진다. 이러한 공동 최적화는 “상태표현이 정책에 유용하도록” 만드는 메커니즘을 제공한다는 점에서 기존에 RNN을 직접 Q‑함수에 삽입한 RL‑RNN/LSTM 방식과 차별화된다.
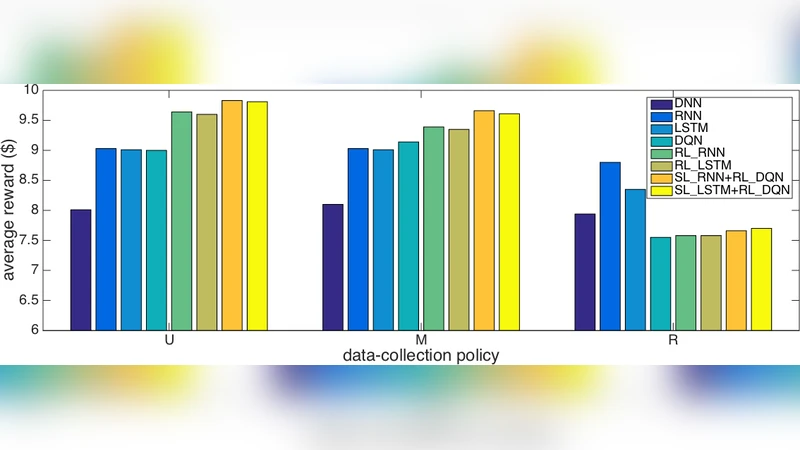
실험에서는 1998 KDD Cup 직접 메일링 데이터셋을 사용하였다. 데이터는 95 k명의 기부자를 23개월에 걸쳐 추적한 2 M개의 전이 튜플을 포함한다. 관측 벡터는 전통적인 RFM(Recency‑Frequency‑Monetary) 특성과 메일링 빈도 두 가지 추가 특성으로 구성된다. 저자는 기존 연구(Tkachenko 2015)의 평가 방식이 정책‑의존적 편향을 초래한다는 점을 비판하고, 관측‑행동‑보상 구조를 이용해 시뮬레이터를 구축한 뒤, 시뮬레이션 환경에서 정책을 평가하였다.
비교 대상은 (1) 선형 Q‑함수를 이용한 배치 Q‑학습, (2) 순수 DQN, (3) RL‑RNN/LSTM, (4) 제안된 SL‑RNN + RL‑DQN 및 SL‑LSTM + RL‑DQN이다. 결과는 하이브리드 모델이 평균 기부액(보상)과 장기 가치(LTV) 측면에서 모든 베이스라인을 크게 앞섰으며, 특히 비선형 상태표현을 통해 숨겨진 고객 행동 패턴을 효과적으로 포착함을 보여준다. 또한, 학습 안정성 측면에서도 순환 네트워크가 초기 상태를 정규화하고, DQN이 급격한 Q‑값 발산을 억제하는 역할을 수행한다는 부가적인 관찰이 있다.
이 논문은 (1) 부분관측 강화학습에서 상태표현 학습을 슈퍼바이즈드 신호와 결합하는 새로운 학습 패러다임, (2) 순환 신경망과 DQN을 결합한 구조가 정책 성능을 실질적으로 향상시킨다는 실증적 증거, (3) 평가 프로토콜의 중요성을 강조하며 시뮬레이터 기반의 오프라인 RL 평가가 필요함을 제시한다는 점에서 의미가 크다. 향후 연구는 (a) 다중 행동 공간 및 연속형 보상에 대한 확장, (b) 메모리‑효율적인 트랜스포머 기반 상태표현, (c) 실제 운영 환경에서 온라인 업데이트와 탐색‑활용 균형을 다루는 실시간 학습 메커니즘을 탐색할 여지를 남긴다.
댓글 및 학술 토론
Loading comments...
의견 남기기