윈그라드 최소 필터링을 이용한 고속 CNN 알고리즘
초록
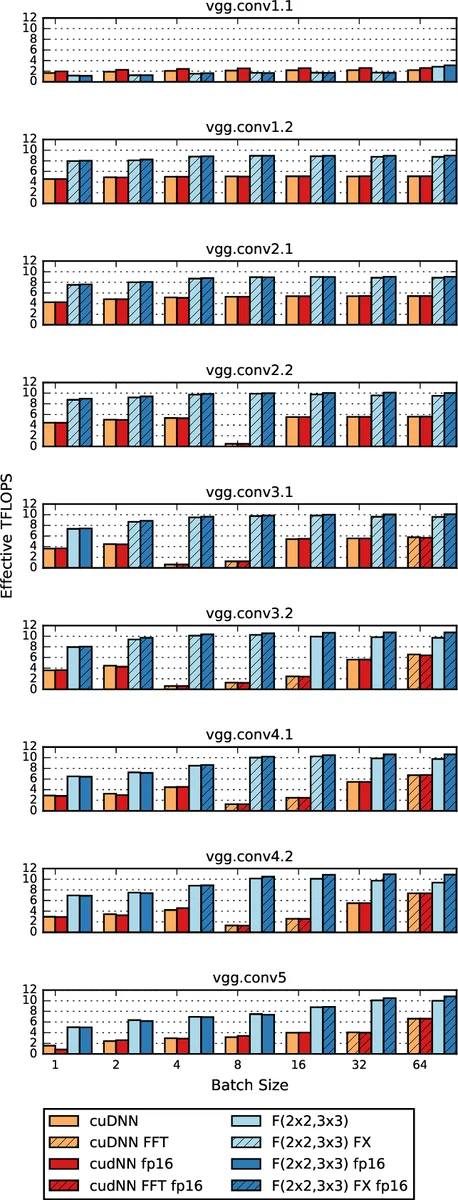
윈그라드 최소 필터링을 활용해 작은 3×3 커널과 작은 배치에서도 높은 처리량을 달성한다. GPU 구현은 VGG 네트워크에서 배치 1~64까지 기존 FFT 기반보다 2배 이상 빠른 속도를 보인다.
상세 분석
이 논문은 컨볼루션 신경망에서 가장 빈번히 사용되는 3×3 필터와 소규모 배치에 최적화된 새로운 연산 방식을 제시한다. 핵심은 윈그라드(Winograd)의 최소 필터링 알고리즘 F(m,r) 으로, 입력 m+r‑1 개의 데이터에 대해 m+r‑1 개의 곱셈만 필요하다는 수학적 최소 복잡도를 이용한다. 1차원 알고리즘을 겹쳐 2차원 F(m×n, r×s) 를 만들면 전체 곱셈 수는 (m+r‑1)(n+s‑1) 으로, 전통적인 직접 컨볼루션 m·n·r·s 에 비해 최대 4배까지 감소한다.
구체적으로 논문은 F(2×2, 3×3) 알고리즘을 구현해 2×2 출력 타일을 4×4 입력 타일에서 계산한다. 변환 행렬 Bᵀ, G, Aᵀ 를 사용해 데이터와 필터를 각각 변환한 뒤, 변환된 행렬을 요소별 곱셈(점곱)하고 다시 역변환한다. 이 과정은 대부분 고밀도 GEMM 연산으로 구현되므로 배치가 작아도 GPU의 연산 유닛을 효율적으로 활용한다.
또한 F(3×3, 2×2) 및 F(4×4, 3×3) 같은 더 큰 타일도 제시했으며, 타일이 커질수록 변환 단계의 부가 연산(덧셈·상수 곱)과 메모리 사용량이 급격히 늘어나 수치적 정확도가 저하될 위험이 있음을 지적한다. 따라서 실용적인 구현에서는 F(2×2, 3×3) 타일이 가장 좋은 트레이드오프를 제공한다.
FFT 기반 컨볼루션과도 비교했는데, FFT는 복소수 곱셈이 필요해 실제 실수 연산 기준으로 최소 2 배 이상의 곱셈 비용이 든다. 윈그라드 방식은 입력당 1 실수 곱셈만 필요하므로, 동일 타일 크기에서도 연산량이 현저히 적다. FFT의 경우 변환 오버헤드와 복소수 연산 때문에 큰 타일을 사용해야 경쟁력이 있지만, 큰 타일은 변환 비용과 수치 오류가 급증한다는 단점이 있다.
GPU 구현에서는 max 16 MB 워크스페이스만 사용하면서 배치 1~64 에 걸쳐 VGG‑16 모델 전체를 처리했으며, 표 1·2에 제시된 실험 결과는 기존 cuDNN FFT 기반보다 평균 2.2× ~ 4.3× 빠른 처리량을 보여준다. 또한 메모리 사용량이 적어 모바일·임베디드 환경에도 적용 가능성이 높다.
전체적으로 이 논문은 수학적 최소 복잡도 이론을 실제 딥러닝 프레임워크에 성공적으로 매핑했으며, 작은 필터·작은 배치 상황에서의 실시간 추론 요구를 만족시키는 실용적인 솔루션을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기