언어 복잡성 탐구: 영어와 폴란드어 텍스트의 순위‑빈도 분석
초록
본 연구는 영어와 폴란드어 문학 텍스트의 단어 순위‑빈도 분포를 조사하고, 저자·번역·품사별 차이가 Zipf 법칙의 스케일링에 미치는 영향을 분석한다. 동일 저자의 폴란드어 코퍼스와 다중 저자 코퍼스, 번역 텍스트와 원어 텍스트를 비교했을 때, 다중 저자·번역 코퍼스에서 스케일링이 더 크게 깨지는 것을 발견했다. 또한 영국 국가 말뭉치를 이용해 형태소(lemma)와 품사별 빈도 분포를 살펴본 결과, 동사만이 독립적으로 약한 스케일링을 보였으며, 다른 품사는 스케일링이 나타나지 않았다.
상세 분석
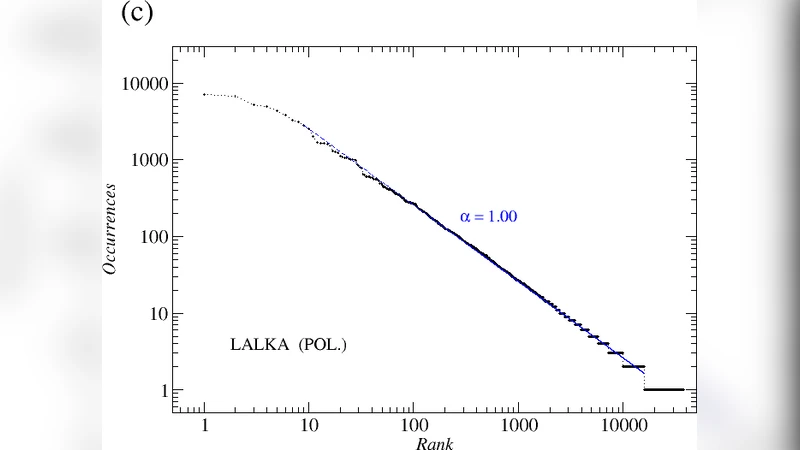
이 논문은 언어 통계학에서 오래전부터 관찰된 Zipf 법칙, 즉 단어의 순위와 빈도가 역비례 관계를 보인다는 가설을 정량적으로 검증한다. 저자는 먼저 영문과 폴란드어의 대표적인 문학 작품들을 선택해 각각의 텍스트를 토큰화하고, 어휘 빈도를 계산한 뒤 로그‑로그 플롯으로 순위‑빈도 곡선을 그렸다. 두 언어 모두 중간 순위 구간(대략 10^210^4)에서는 전형적인 -1 기울기의 직선형 스케일링을 보였으며, 이는 전통적인 Zipf 지수와 일치한다. 그러나 고빈도(상위 1020개)와 저빈도(10^4 이하) 구간에서는 뚜렷한 편차가 나타났는데, 이는 어휘 다양성, 텍스트 길이, 그리고 형태소 구조 차이에 기인한다는 저자의 해석이 설득력을 가진다.
다음으로 저자는 폴란드어 텍스트를 두 종류의 코퍼스로 나누어 비교했다. 첫 번째는 동일 작가가 쓴 여러 작품으로 구성된 ‘단일 저자 코퍼스’, 두 번째는 서로 다른 작가들의 작품을 모은 ‘다중 저자 코퍼스’이다. 두 코퍼스 모두 동일한 총 토큰 수와 비슷한 장르적 특성을 유지하도록 조정했음에도 불구하고, 다중 저자 코퍼스에서는 스케일링이 더 크게 깨졌다. 이는 작가마다 고유한 어휘 선택과 스타일이 존재함을 통계적으로 입증하는 증거로, 코퍼스 구성 시 저자 다양성이 Zipf 법칙의 적용 범위를 제한한다는 중요한 시사점을 제공한다.
또한 번역 텍스트와 원어 텍스트를 비교한 결과, 폴란드어로 번역된 외국어 문학 작품은 원어 폴란드어 텍스트에 비해 스케일링 파괴가 더욱 심했다. 번역 과정에서 발생하는 어휘 재배치, 의역, 그리고 번역가의 개인적 선택이 빈도 분포에 비선형적인 변형을 가한다는 점을 강조한다. 이는 번역 연구와 자연어 처리에서 번역 데이터의 통계적 특성을 고려해야 함을 시사한다.
마지막으로 영국 국가 말뭉치(BNC)를 활용해 형태소(lemma)와 품사(part‑of‑speech)별로 순위‑빈도 분포를 분석했다. 전체 어휘를 그대로 사용할 때는 여전히 Zipf‑like 스케일링이 관찰되지만, 각 품사를 별도로 추출하면 대부분의 품사(명사, 형용사, 부사 등)는 스케일링이 사라진다. 유일하게 동사만이 약한 직선 구간을 유지하는데, 이는 동사가 문장 구조와 의미 전달에서 중심적인 역할을 하며, 사용 빈도가 비교적 고르게 분포되는 특성 때문이라고 해석한다. 이러한 결과는 언어 모델링에서 품사별 빈도 특성을 반영하는 것이 필요함을 보여준다.
전반적으로 이 연구는 Zipf 법칙이 언어 전반에 걸쳐 보편적이지만, 텍스트의 메타데이터(저자, 번역 여부, 품사 등)에 따라 그 적용 범위와 정확도가 크게 달라질 수 있음을 실증적으로 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기