ISO 언어자원 표준 13년의 성과와 미래 전망
초록
ISO TC 37/SC 4가 지난 13년간 수행한 디지털 언어자원 관리 프로젝트를 정리하고, 축적된 기술 경험을 바탕으로 향후 표준화 흐름과 주요 과제를 제시한다.
상세 분석
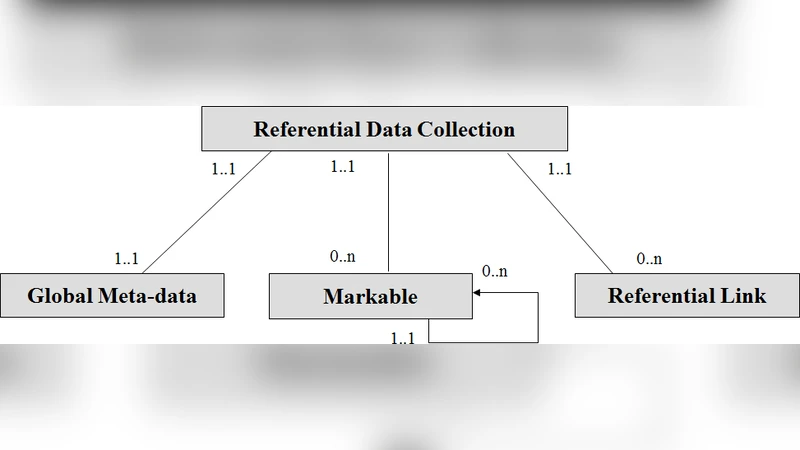
이 논문은 ISO TC 37/SC 4가 주도한 언어자원 표준화 작업을 연대기적으로 검토하면서, 기술적·사회적 맥락에서 어떤 교훈을 얻었는지를 심층적으로 분석한다. 먼저 초기 단계에서는 전통적인 사전·용어집을 전자화하기 위한 ISO 24613(LMF)과 ISO 24610(용어 데이터 모델) 등 구조화된 메타데이터 스키마가 개발되었다. 이들 표준은 언어자원의 내부 일관성을 확보하고, 서로 다른 기관·도메인 간 데이터 교환을 가능하게 하는 기반을 제공한다. 이후에는 코퍼스 주석을 위한 ISO 24614(주석 프레임워크)와 ISO 24615(다층 주석) 등이 도입돼, 말뭉치의 형태소·구문·의미 레벨을 통합적으로 기술할 수 있게 되었다. 특히 ‘데이터 카테고리 사전(DC‑DC)’을 중심으로 한 메타데이터 표준화는 다국어·다문화 환경에서 용어와 의미의 정확한 매핑을 지원한다.
프로젝트 진행 과정에서 저자들은 표준의 채택을 촉진하기 위해 TEI(텍스트 인코딩 이니셔티브)와의 연계, 오픈소스 툴킷 제공, 그리고 교육·워크숍을 통한 커뮤니티 구축에 힘썼다. 이러한 활동은 표준이 단순히 문서화된 규격에 머무르지 않고 실제 언어공학 파이프라인에 통합되는 데 기여했다.
미래 전망 파트에서는 현재 AI·딥러닝 기반 언어 모델이 급부상함에 따라, 기존 표준이 ‘데이터의 FAIR 원칙(Findable, Accessible, Interoperable, Reusable)’을 충족하도록 확장될 필요가 있음을 강조한다. 구체적으로는 메타데이터의 자동 생성, 링크드 데이터(LD)와 시맨틱 웹 기술과의 연계, 그리고 대규모 학습 코퍼스의 윤리·프라이버시 관리 메커니즘이 표준화 작업에 포함될 것으로 예상한다. 또한, 다언어·다문화 자원의 지속 가능한 관리와 저작권 문제 해결을 위한 국제 협력 모델이 제시된다.
결론적으로, 저자들은 지난 13년간 구축된 표준이 언어자원 관리의 기술적 토대를 마련했으며, 앞으로는 보다 유연하고 확장 가능한 구조와, AI 시대에 부합하는 데이터 거버넌스 프레임워크가 핵심 과제가 될 것이라고 제언한다.