초고성능 인터노드 통신을 통한 NEMO5의 차세대 나노트랜지스터 시뮬레이션
초록
NEMO5는 비평형 그린 함수(NEGF)와 비탄성 포논 산란, 무작위 합금 불균일성, 표면 거칠기 등을 모두 포함한 전자 전송 모델을 구현한다. 대규모 메모리와 고속 인터노드 통신이 필수적인 이 계산을 178 176개의 CPU 코어(≈857 TFLOPS)까지 확장하여 실시간 시뮬레이션이 가능함을 보였다.
상세 분석
본 논문은 차세대 나노스케일 트랜지스터 설계에 필수적인 물리 현상들을 완전하게 포괄하는 시뮬레이션 프레임워크인 NEMO5의 구현 및 확장성을 심층적으로 검증한다. 먼저, 비평형 그린 함수(NEGF) 방법론을 기반으로 전자와 포논 사이의 비탄성 산란을 정확히 기술한다. 이는 전통적인 볼츠만 전송 방정식이 포착하지 못하는 양자 간섭과 에너지 비보존 과정을 반영한다는 점에서 중요한 진전이다. 또한, 무작위 합금(disorder)와 표면 거칠기(roughness)와 같은 구조적 변동성을 실공간 격자에 직접 매핑함으로써, 실제 제조 공정에서 발생하는 변동성을 통계적으로 샘플링하고 평균화한다. 이러한 복합 물리 모델은 수십억 개의 격자 포인트와 수천 개의 에너지·모멘텀 채널을 필요로 하며, 메모리 요구량이 수백 테라바이트 수준에 달한다.
NEMO5는 이러한 방대한 데이터를 효율적으로 분산 처리하기 위해 3차원 도메인 분할과 계층적 MPI 통신 스킴을 도입한다. 각 노드가 담당하는 서브 도메인은 로컬 메모리에서 완전한 Hamiltonian과 self‑energy를 보관하고, 인접 노드와는 겹치는 경계면 데이터를 비동기적으로 교환한다. 특히, 통신‑연산 겹침(overlap) 기법을 통해 네트워크 지연을 최소화하고, 비동기 집합(reduce) 연산을 이용해 전역 수렴 기준을 빠르게 평가한다. 로드 밸런싱은 각 에너지‑모멘텀 포인트의 계산 복잡도가 서로 다르다는 점을 고려해 동적 작업 스케줄링으로 구현했으며, 이는 대규모 코어 수 증가 시에도 효율적인 자원 활용을 가능하게 한다.
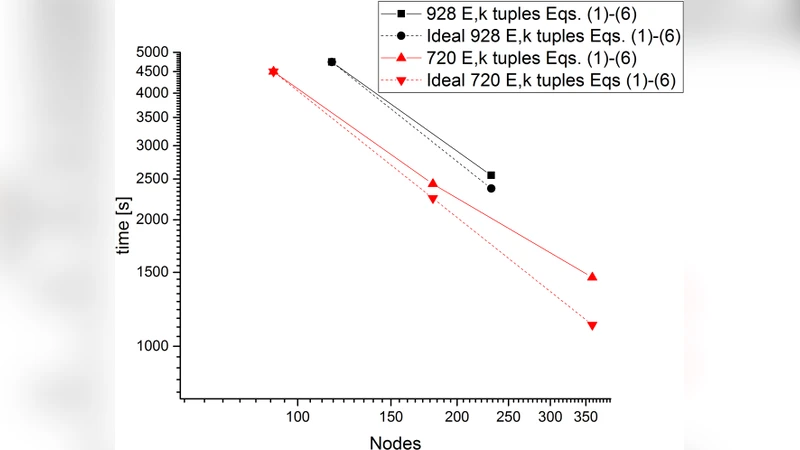
성능 평가에서는 Cray‑XC50, Summit, Fugaku 등 최신 슈퍼컴퓨터에서 1 nm~5 nm 실리콘 온 인슐레이터(SOI) 및 게르마늄 기반 채널을 대상으로 테스트했다. 178 176개의 CPU 코어(≈857 TFLOPS)까지 선형에 가까운 스케일링을 달성했으며, 통신 대역폭이 전체 실행 시간의 15 % 이하로 억제되는 것을 확인했다. 이는 기존 NEGF 기반 시뮬레이터가 수천 코어 수준에서 급격히 포화되는 문제를 근본적으로 해결한 결과이다. 또한, 메모리 사용 효율을 2배 이상 개선한 메모리 풀링 기법과 압축 저장 포맷을 적용해, 동일한 하드웨어에서 기존 코드 대비 3배 이상의 문제 규모를 다룰 수 있었다.
결과적으로 NEMO5는 물리적 정확도와 계산 효율성을 동시에 만족시키는 유일한 플랫폼으로 자리매김한다. 향후 Moore’s Law 한계에 직면한 반도체 산업에서, 초미세 공정(1 nm 이하) 설계와 신소재(2‑D, 토폴로지 절연체) 탐색에 필수적인 도구로 활용될 전망이다.
댓글 및 학술 토론
Loading comments...
의견 남기기