상관 신경망을 활용한 다중뷰 공통 표현 학습
CorrNet은 두 개의 뷰(또는 모달리티)에서 공통 잠재 공간을 학습하면서, 자기·교차 재구성을 최소화하고 숨김 표현 간의 상관을 최대화한다. 자동인코더 구조에 상관 정규화를 추가해 CCA의 장점과 확장성을 결합했으며, 단일 뷰 데이터 활용, 미니배치 SGD 기반 학습, 깊은 층 확장 등을 지원한다. 실험에서는 MNIST, 다국어 문서 분류, 문자 전사 매칭, 빅그램 유사도 등 네 가지 과제에서 기존 CCA·KCCA·MAE·Deep CCA 등…
저자: Sarath Ch, ar, Mitesh M. Khapra
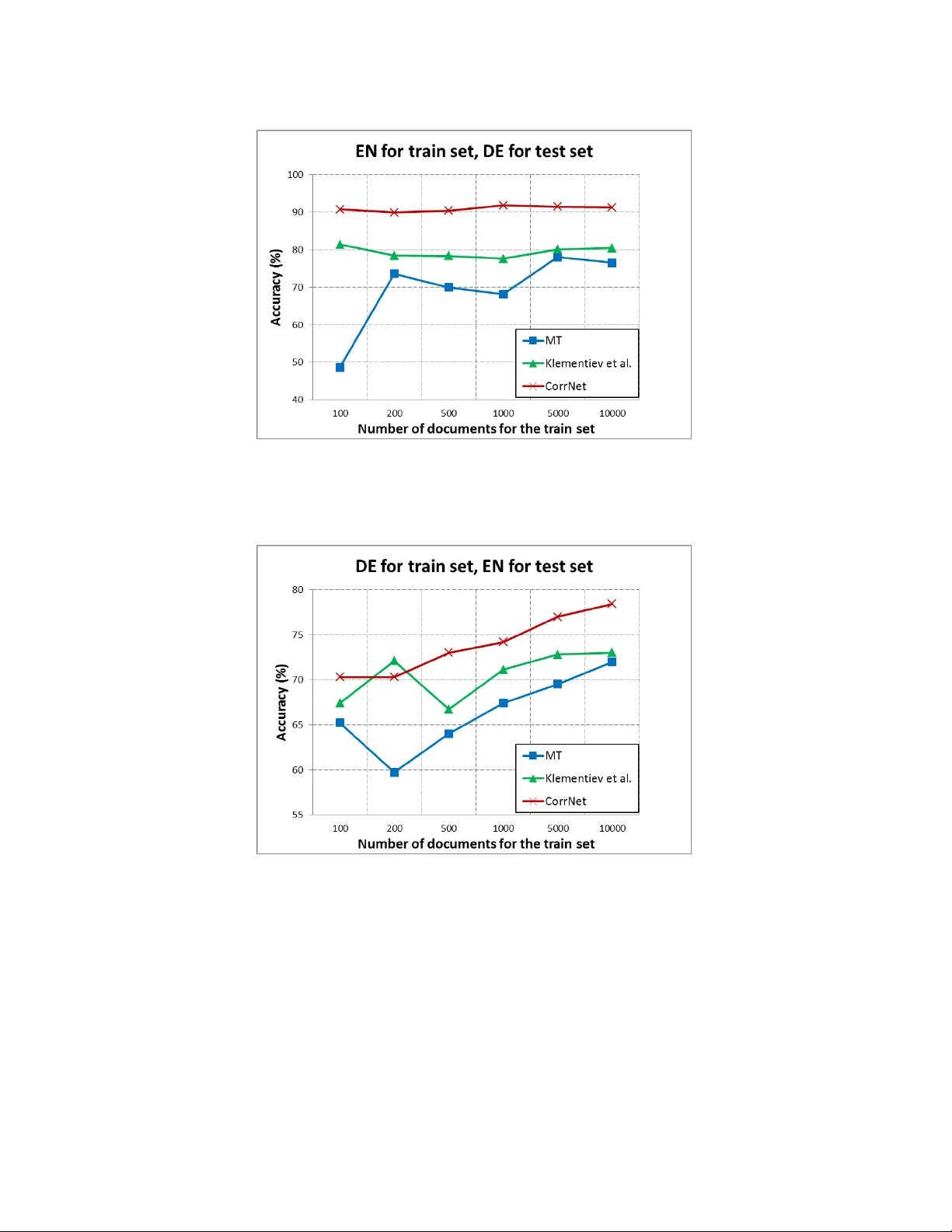
본 논문은 다중뷰(또는 다중모달) 데이터에 대해 공통 잠재 표현을 학습하는 새로운 방법인 Correlational Neural Network(CorrNet)를 제안한다. 기존 연구는 크게 두 갈래로 나뉜다. 첫 번째는 Canonical Correlation Analysis(CCA)와 그 변형으로, 두 뷰를 선형 변환한 뒤 상관을 최대화해 공통 표현을 얻는다. CCA는 뷰 간 상관을 직접 최적화하므로 전이 학습에 강점이 있지만, 대규모 데이터에 비효율적이며 재구성 능력이 부족하고, 단일 뷰 데이터 활용이 어렵다. 두 번째는 Multimodal Autoencoder(MAE)와 같은 자동인코더 기반 방법으로, 입력을 결합해 숨김층에 매핑하고 자기·교차 재구성을 학습한다. MAE는 재구성 능력이 뛰어나지만, 뷰 간 표현을 동일한 잠재 공간에 강제하지 않아 상관이 낮고 전이 학습에 약하다.
CorrNet은 이 두 접근법을 하나의 신경망 구조와 손실 함수에 통합한다. 모델은 입력층(두 뷰를 연결), 숨김층(공통 차원 k), 출력층(두 뷰를 동시에 복원)으로 구성된다. 숨김 표현은 h(z)=f(Wx+Vy+b) 로 계산되며, 여기서 W와 V는 각각의 뷰에 대한 선형 투영 행렬, f는 비선형 활성화 함수(예: sigmoid, tanh)이다. 출력은 g(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기