XL‑mHG 검증: 대용량 순위 바이너리 리스트의 효율적 풍부성 탐지
초록
본 논문은 최소 하이퍼지오메트릭 테스트(mHG)의 정의와 정확한 p‑값을 빠르게 계산하는 알고리즘을 상세히 설명하고, 이를 확장한 XL‑mHG를 제안한다. XL‑mHG는 최소 서브셋 크기 X와 검사 범위 L을 추가 제어함으로써 풍부성 검정의 특수성을 조절한다. 구현 세부사항과 동적 프로그래밍 기반의 경로‑계산 기법을 제시하며, GO‑PCA와 같은 유전자 발현 분석에 적용 가능함을 보인다.
상세 분석
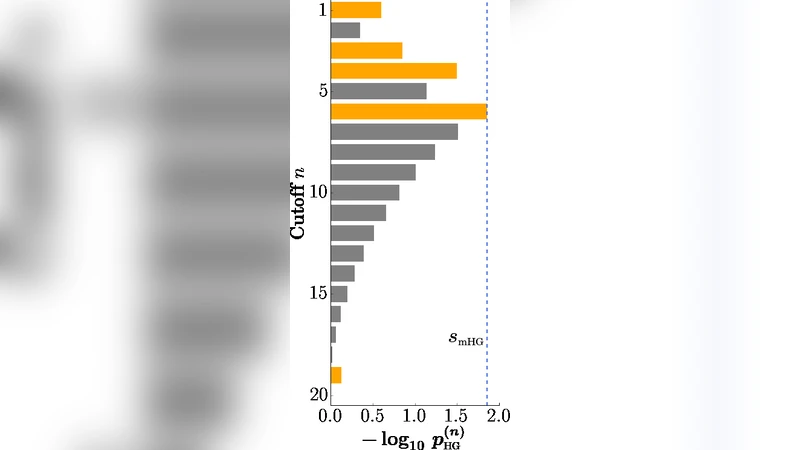
이 논문은 mHG 테스트를 비모수적 풍부성 검정으로 재정의하고, 기존 단순 하이퍼지오메트릭 검정이 갖는 ‘컷오프 n 선택’이라는 주관적 파라미터 문제를 완전히 해소한다. mHG는 모든 가능한 앞부분 n(1≤n≤N)에 대해 하이퍼지오메트릭 p‑값 p_HG(n)을 계산하고, 그 최소값 s_mHG를 테스트 통계량으로 채택한다. 이때 다중 검정 문제는 동적 프로그래밍을 이용한 경로‑계산으로 정확히 보정되며, Lipson 상한 p_mHG ≤ K·s_mHG 가 제공되어 계산량을 크게 줄인다.
XL‑mHG는 두 개의 추가 파라미터 X와 L을 도입한다. X는 “최소 풍부성 서브셋 크기”를 제한해, 너무 작은 부분집합에 의한 과도한 유의성을 방지한다. L은 리스트의 상위 L 위치까지만 검정 대상으로 제한함으로써, 전체 리스트에 퍼진 잡음에 의한 왜곡을 억제한다. 알고리즘적으로는 mHG의 경로‑계산 테이블을 X와 L에 맞게 마스킹하고, 허용된 n에 대해서만 최소 p‑값을 탐색하도록 수정한다. 이 과정에서 복잡도는 O(N·K) 수준을 유지하면서도, 실제 생물학적 데이터(수천~수만 개 유전자)에서 밀리초 내에 결과를 도출한다.
논문은 또한 풍부성 강도 점수 e_mHG와 e_XL‑mHG를 정의하여, 단순 p‑값 외에 효과 크기를 정량화한다. 이 점수는 s_mHG와 p_mHG를 결합해 로그‑스케일로 변환한 형태이며, 결과 해석에 직관성을 제공한다. 구현은 Cython 기반 오픈소스로 제공되어, 파이썬 환경에서 손쉽게 호출 가능하고, 메모리 사용량도 효율적이다.
전체적으로, XL‑mHG는 mHG의 강력한 비모수적 특성을 유지하면서, 실제 응용에서 흔히 발생하는 ‘작은 서브셋에 의한 과대평가’와 ‘전체 리스트에 대한 불필요한 검정’ 문제를 파라미터 X와 L으로 제어한다. 이는 GO‑PCA와 같은 사전 지식 기반 유전자 발현 분석 파이프라인에서, 의미 있는 GO 용어를 정확히 추출하고, 가짜 양성률을 낮추는 데 크게 기여한다.
댓글 및 학술 토론
Loading comments...
의견 남기기