다중 도메인 음성 인식을 위한 데이터 선택 전이 학습
초록
본 논문은 음성 인식 모델 학습 시 발생하는 부정 전이를 완화하기 위해, 목표 테스트 셋과 음향적으로 유사한 훈련 발화를 선택하는 서브모듈러 기반 데이터 선택 방법을 제안한다. 목표 도메인별 likelihood‑ratio를 이용해 서브모듈러 함수 fLR을 정의하고, 그리디 알고리즘으로 최적의 훈련 서브셋을 추출한다. 6개 도메인(라디오, TV, 전화, 회의, 강의, 읽기)으로 구성된 60시간 데이터셋에서 실험했으며, PLP 기반 모델에서 4 %·DNN‑BN 기반 모델에서 2 %의 상대적 WER 감소를 달성하였다.
상세 분석
이 연구는 자동 음성 인식(ASR) 시스템이 다중 도메인 환경에서 겪는 ‘부정 전이(negative transfer)’ 문제를 근본적으로 해결하고자 한다. 기존의 MLE 기반 GMM‑HMM 학습은 데이터 양이 무한히 많을 때 최적 성능을 보장하지만, 실제로는 도메인 간 음향 차이와 발화 스타일 차이 때문에 추가 데이터가 오히려 성능을 저하시킬 수 있다. 논문은 이러한 현상을 정량화하고, 도메인별 전이 효과를 시각화함으로써 부정 전이가 언제, 어디서 발생하는지를 명확히 제시한다.
핵심 기법은 두 개의 GMM을 학습하는 것이다. 하나는 목표 테스트 셋을 기반으로 한 ‘타깃 모델(Θ_tgt)’, 다른 하나는 전체 60시간 훈련 데이터를 이용한 ‘배경 모델(Θ_Ω)’이다. 각 훈련 발화 O에 대해 프레임 단위 likelihood ratio를 계산하고, 이를 기하 평균으로 통합해 LR(O)를 얻는다. 이후 LR(O)의 합을 서브모듈러 함수 f_LR(S)=∑_{O∈S}LR(O) 로 정의한다. f_LR은 모듈러이면서 비감소(monotonic) 특성을 가지므로, 그리디 선택 알고리즘을 적용하면 (1‑1/e)≈63 %의 근사 보장을 얻는다.
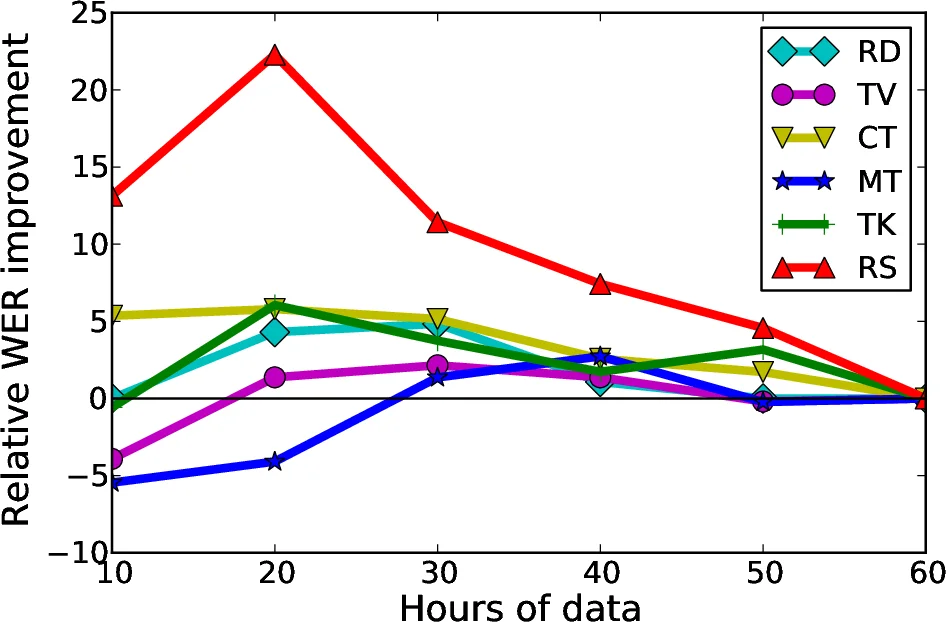
예산 기반 선택에서는 사전에 정의된 시간(10,20,30,40,50 h) 한도 내에서 가장 높은 LR 값을 가진 발화를 순차적으로 추가한다. 실험 결과, 예산이 증가할수록 WER가 개선되지만 일정 시점을 넘어서는 부정 전이가 다시 나타나 전체 성능이 수렴한다는 점을 확인했다. 자동 예산 결정 방식은 LR 값들의 분포에 512‑mixture GMM을 피팅하고, 가장 큰 가중치를 가진 혼합 성분의 평균을 임계값으로 삼아 LR이 이를 초과하는 발화만 선택한다. 이 방법은 도메인마다 최적의 데이터 양을 자동으로 추정해, 고정 예산(30 h)보다 일관되게 더 나은 결과를 제공한다.
특히, PLP+BN(딥 뉴럴 네트워크 기반 bottleneck) 특징을 사용했을 때는 전반적인 WER가 크게 낮아졌으며, 데이터 선택에 따른 상대적 개선폭도 PLP 단독 대비 약 2 %포인트 상승했다. 이는 서브모듈러 기반 선택이 딥러닝 전처리와도 잘 결합될 수 있음을 시사한다.
또한, 선택된 서브셋을 분석한 결과, 대부분의 발화가 동일 도메인에서 추출되었지만, 일부 교차 도메인 발화가 포함되어 긍정 전이가 발생함을 확인했다. 예를 들어, 라디오 테스트에 TV와 읽기 발화가, 강의 테스트에 TV 발화가 선택되는 식이다. 이는 단순히 도메인 라벨만으로는 포착하기 어려운 음향적 유사성을 LR이 효과적으로 반영한다는 증거다.
마지막으로, 저자는 현재 선택 함수가 음향 유사도에만 초점을 맞추고 있어, 음소 분포 편향을 방지하기 위한 추가적인 서브모듈러(예: phonetic coverage)와 결합이 필요함을 언급한다. 또한, 최소 음소 오류(MPE)와 같은 판별적 학습 기준에 맞는 새로운 서브모듈러 설계도 향후 연구 과제로 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기