스트림 의견 문서의 능동적 증분 학습 ACOSTREAM
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
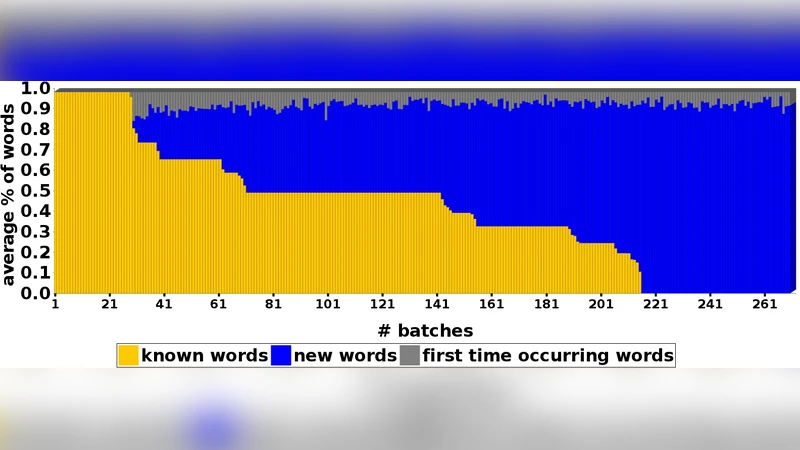
본 논문은 제한된 라벨만을 이용해 트위터·리뷰와 같은 의견 스트림을 지속적으로 학습하는 ACOSTREAM 모델을 제안한다. 초기 라벨된 시드 문서를 기반으로 다항 나이브 베이즈 분류기를 구축하고, 정보이득 또는 불확실성 기반 샘플링 전략으로 필요 시 전문가에게 라벨을 요청한다. 실험을 통해 적은 라벨 비용으로도 높은 분류 성능을 유지함을 보인다.
상세 분석
ACOSTREAM은 의견 스트림 마이닝에서 두 가지 핵심 문제, 즉(1) 시간에 따라 변하는 어휘와(2) 라벨 확보 비용이 높은 상황을 동시에 해결한다는 점에서 의미가 크다. 기본 분류기로 다항 나이브 베이즈(MNB)를 선택한 이유는 단어‑클래스 통계의 증분 업데이트가 매우 효율적이며, 라플라스 평활을 통해 희소 단어 문제를 완화할 수 있기 때문이다. 초기 시드 집합 S에서 추출한 어휘 V와 각 단어‑클래스 카운트 N_ic, 클래스 카운트 N_c를 이용해 사후 확률 ˆP(c|d)∝ˆP(c)∏ˆP(w_i|c)를 계산하고, 이를 통해 새로운 문서 d의 라벨을 예측한다.
능동 학습 단계에서는 두 가지 샘플링 전략을 제안한다. 첫 번째는 정보이득(Information Gain) 기반으로, 문서 d가 현재 관찰된 단어‑클래스 분포에 미치는 엔트로피 감소량을 계산한다. IG(d)=∑_{w_i∈d∩V}
댓글 및 학술 토론
Loading comments...
의견 남기기