주의 기반 신경망을 이용한 문장 요약 모델
초록
본 논문은 입력 문장을 직접 인코딩하고, 단어별 주의 메커니즘을 통해 요약을 생성하는 완전 데이터‑구동식 신경망 모델을 제안한다. 간단한 구조에도 불구하고 대규모 학습이 가능하며, DUC‑2004와 Gigaword 헤드라인 생성 과제에서 기존 추출·추상 방식들을 크게 능가한다.
상세 분석
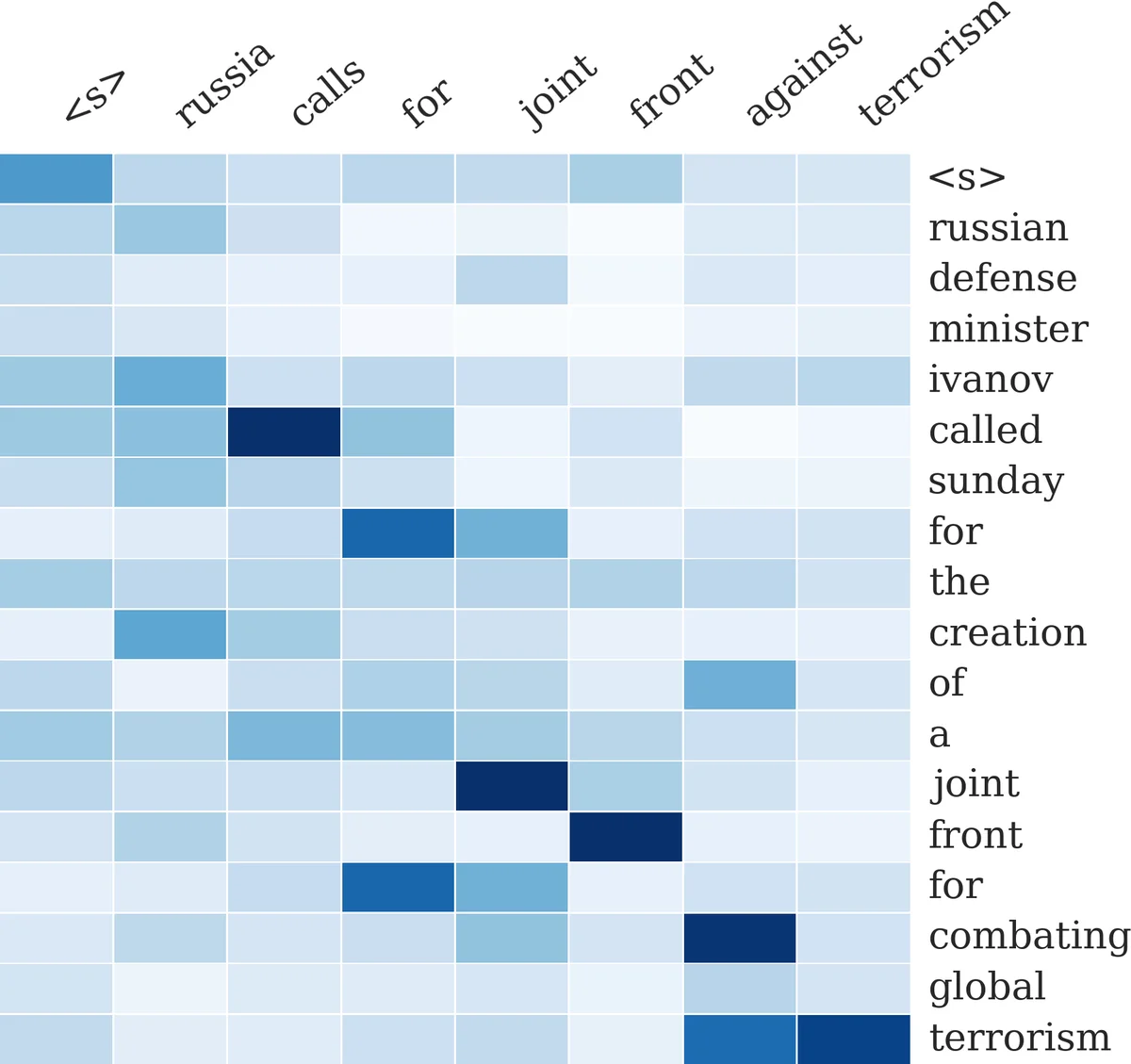
이 연구는 문장 수준 요약을 ‘조건부 언어 모델’로 정의하고, 입력 문장을 컨텍스트 인코더에 의해 실시간으로 가중합하는 방식으로 구현한다. 기본 디코더는 전통적인 피드‑포워드 신경 언어 모델(NNLM) 구조를 따르며, 현재 요약 컨텍스트 y_c와 입력 전체 x 를 결합해 다음 단어 y_{i+1} 의 확률을 예측한다. 인코더는 세 가지 변형을 제시한다. 첫 번째는 입력 전체를 평균화한 Bag‑of‑Words 인코더로, 단어 중요도만을 학습한다. 두 번째는 1‑차원 컨볼루션(TDNN)과 풀링을 겹쳐 지역적 패턴을 포착하는 Convolutional 인코더이며, 이는 순서 정보를 어느 정도 보존한다. 세 번째이자 핵심인 Attention‑Based 인코더는 입력 토큰마다 현재 요약 컨텍스트와의 내적을 통해 소프트 정렬 가중치 p 를 계산하고, 가중합된 입력 표현을 디코더에 전달한다. 이는 Bahdanau et al.의 기계 번역 어텐션을 단순화한 형태로, 정렬 매트릭스 P 와 스무딩 윈도우 Q 를 학습한다.
학습은 요약‑입력 쌍에 대한 음의 로그우도(NLL)를 미니배치 SGD로 최소화하며, 전체 모델이 하나의 엔드‑투‑엔드 파이프라인으로 최적화된다. 생성 단계에서는 Viterbi와 유사한 정확한 탐색이 이론적으로 가능하지만 어휘 V 가 크므로 실용적으로는 빔 서치를 적용한다. 빔 크기 K 와 요약 길이 N 에 따라 O(K · N · |V|) 의 복잡도를 갖지만, 각 단계의 확률 계산을 배치 연산으로 묶어 효율을 크게 높인다.
추출적 요소를 보완하기 위해 로그선형 모델 형태의 가중치 α 를 도입하고, 입력 단어와의 unigram·bigram·trigram 매칭, 순서 재배열 등을 특징으로 추가한다. 이 파라미터는 최소 오류율 학습(MERT)으로 요약 평가 지표에 맞춰 튜닝한다.
실험에서는 약 4백만 개의 기사‑헤드라인 쌍을 포함한 Gigaword 코퍼스로 사전 학습하고, DUC‑2004 요약 과제에서 ROUGE‑1·2·L 점수가 기존 통계·구문 기반 시스템과 기계 번역 기반 베이스라인을 크게 앞선다. 특히 어휘가 제한된 추출 기반 모델이 놓치기 쉬운 의미 재구성·패러프레이징을 자연스럽게 수행한다는 점이 강조된다. 전체적으로 모델은 구조가 단순하면서도 대규모 데이터와 병렬 연산에 최적화되어, 추후 다양한 요약·생성 작업에 확장 가능성을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기