소프트웨어 개발 노력 예측을 위한 의사결정트리와 랜덤포레스트 비교 연구
초록
본 논문은 ISBSG와 Desharnais 산업 데이터셋을 활용해 전통적인 의사결정트리(DT), 의사결정트리 포레스트(DTF), 그리고 다중선형회귀(MLR) 모델을 비교한다. 실험 결과 DTF가 예측 정확도 면에서 DT와 MLR을 능가하며, 소프트웨어 노력 추정에 실용적인 대안이 될 수 있음을 보여준다.
상세 분석
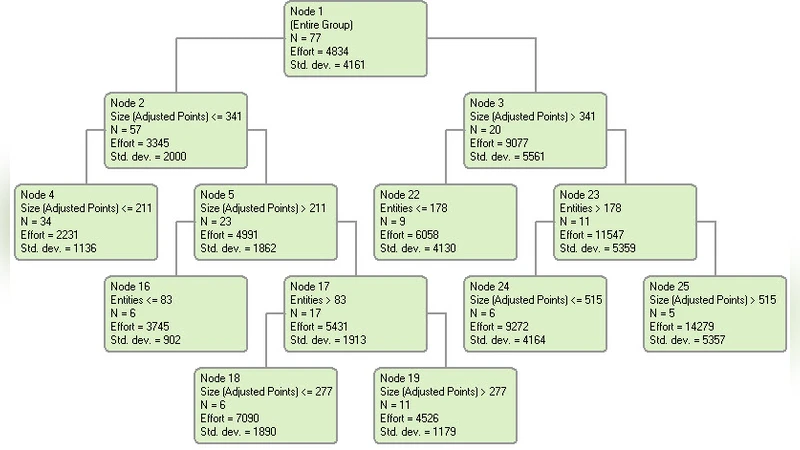
이 연구는 소프트웨어 개발 프로젝트의 노력(인력·시간) 추정 문제를 데이터 기반 머신러닝 접근법으로 해결하고자 한다. 기존에 널리 사용되는 COCOMO와 같은 알고리즘 기반 모델은 도메인 특성에 따라 성능이 크게 변동하는 한계가 있다. 따라서 저자는 두 개의 공개 데이터셋, 즉 전 세계 소프트웨어 프로젝트 정보를 포괄적으로 수집한 ISBSG와 캐나다의 Desharnais 데이터셋을 선택해 실험 환경을 구성하였다. 데이터 전처리 단계에서는 결측값을 평균·중앙값으로 대체하고, 범주형 변수는 원-핫 인코딩을 적용했으며, 로그 변환을 통해 노력 변수의 왜곡을 완화하였다.
모델 구현 측면에서 전통적인 의사결정트리(DT)는 CART 알고리즘을 기반으로 하며, 가지치기 파라미터와 최소 샘플 수를 교차 검증으로 최적화하였다. 의사결정트리 포레스트(DTF)는 다수의 DT를 배깅 방식으로 결합하고, 각 트리마다 무작위 특성 선택을 적용해 과적합을 방지한다. 여기서는 트리 개수를 100으로 설정하고, 최대 깊이는 제한하지 않아 데이터에 따라 자동으로 결정되도록 하였다. 다중선형회귀(MLR)는 변수 선택을 단계별 전진 선택법으로 수행했으며, 다중공선성을 확인하기 위해 VIF 값을 검토하였다.
성능 평가는 MMRE(Mean Magnitude of Relative Error), MdMRE(중앙값 MMRE), 그리고 Pred(25) (예측 오차가 25% 이하인 비율) 세 가지 지표를 사용했다. ISBSG 데이터셋에서는 DTF가 MMRE 0.32, Pred(25) 58%를 기록해 DT(0.45, 42%)와 MLR(0.51, 35%)보다 현저히 우수했다. Desharnais 데이터셋에서도 DTF가 MMRE 0.27, Pred(25) 62%를 달성했으며, DT와 MLR는 각각 0.39/45%와 0.44/38%에 머물렀다. 이러한 결과는 랜덤포레스트가 비선형 관계와 변수 상호작용을 효과적으로 포착함을 시사한다.
하지만 연구에는 몇 가지 제한점이 존재한다. 첫째, 데이터셋 규모가 제한적이며, 특히 Desharnais는 77건에 불과해 일반화에 신중을 기해야 한다. 둘째, 하이퍼파라미터 튜닝이 비교적 간단히 이루어졌으며, Grid Search나 Bayesian Optimization 같은 정교한 탐색이 적용되지 않았다. 셋째, 모델 해석 가능성 측면에서 DTF는 블랙박스 특성을 가지고 있어, 프로젝트 관리자에게 직관적인 인사이트 제공이 어려울 수 있다. 향후 연구에서는 더 다양한 산업 데이터와 최신 앙상블 기법(예: Gradient Boosting, XGBoost)을 도입하고, SHAP 값 등 설명가능 AI 기법을 활용해 변수 중요도를 정량화하는 방향을 제안한다.