대규모 딥러닝을 위한 드롭아웃 기반 DBN 분산 학습
초록
본 논문은 딥러닝 모델인 깊은 신뢰 네트워크(DBN)의 학습 비용을 줄이기 위해, 무작위 드롭아웃을 클러스터 환경에 적용하고 네 개의 결합 방식을 제안한다. GPU 가속과 모델 병렬화를 결합해 MNIST 실험에서 기존 최첨단보다 낮은 오류율을 달성하였다.
상세 분석
이 연구는 두 가지 핵심 아이디어를 결합한다. 첫째, 기존의 드롭아웃 기법을 단일 머신이 아닌 다수의 머신에 동시에 적용한다는 점이다. 각 머신은 전체 네트워크에서 일정 비율(p)의 뉴런을 무작위로 제외하고, 남은 서브 네트워크만을 학습한다. 이렇게 하면 각 머신이 다루는 파라미터 수가 원래의 1‑p² 배로 감소하므로 메모리와 연산량이 크게 줄어든다. 둘째, 학습된 서브 네트워크들을 하나의 통합 모델로 결합하는 네 가지 방법을 제시한다. (1) 가중치 평균화는 각 머신이 최종적으로 얻은 파라미터를 단순 평균해 전체 모델을 재구성한다. (2) 다수결 투표는 각 서브 모델이 테스트 샘플에 대해 내린 예측을 집계해 최종 라벨을 결정한다. (3) 동기식 파라미터 업데이트는 모든 머신이 매 미니배치 후 중앙 파라미터 서버에서 최신 가중치를 가져와 업데이트하고, 업데이트가 끝날 때까지 다른 머신은 대기한다. (4) 비동기식 업데이트는 각 머신이 독립적으로 파라미터를 읽고 쓰며, 충돌이 발생할 경우 순서를 보장하지 않는다. 비동기식은 통신 오버헤드를 최소화하지만 파라미터 일관성이 떨어져 추가적인 확률적 효과를 만든다.
논문은 기존 모델 병렬화 프레임워크(예: DistBelief)와 비교해 두드러진 장점을 강조한다. DistBelief는 전체 네트워크를 그대로 분할해 빈번한 파라미터 서버와의 통신이 필요하지만, 본 접근법은 드롭아웃으로 네트워크 자체를 축소하므로 통신량이 크게 감소한다. 또한 GPU를 활용해 각 머신 내부의 행렬 연산을 가속화함으로써, 메모리 제한에 걸리지 않는 한 대규모 파라미터도 효율적으로 처리한다.
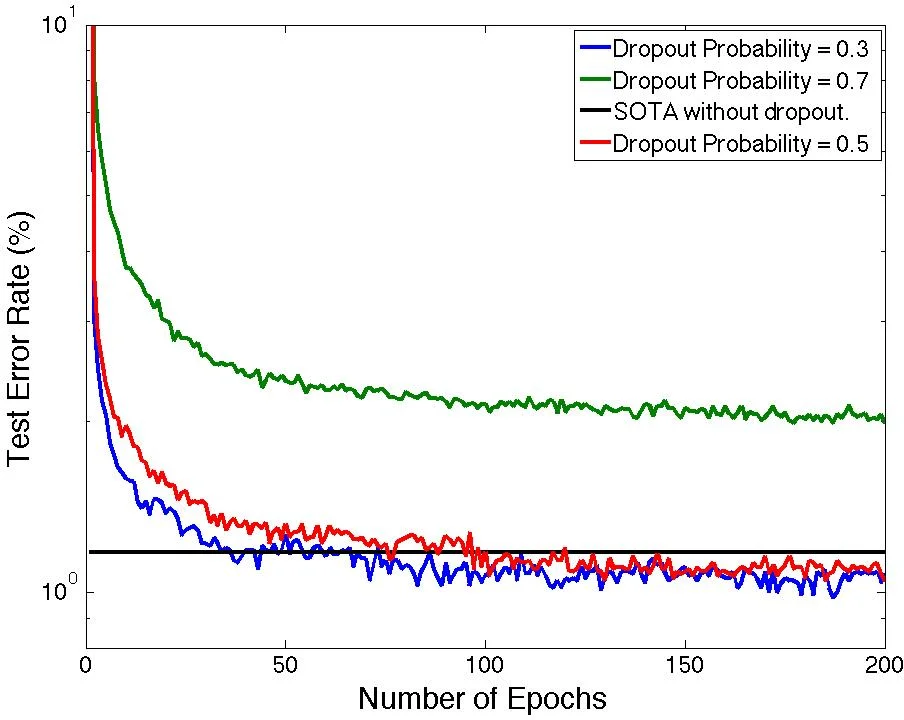
실험에서는 784‑500‑500‑2000‑10 구조의 DBN을 MNIST 데이터에 적용했다. 사전 학습 단계에서 RBM을 50 epoch, 이후 dropout을 적용한 미세 조정 단계에서 200 epoch을 수행했다. 드롭아웃 비율을 0.5로 설정했을 때, 가중치 평균화와 동기식 업데이트가 각각 0.98 %와 0.97 %의 테스트 오류율을 기록해, 기존 최고 성능(1.18 %)을 크게 앞섰다. 비동기식 업데이트는 1.06 %로 다소 낮은 성능을 보였지만, 통신 비용 절감 측면에서 여전히 유용하다. 또한 드롭아웃 비율을 0.6 이상으로 높이면 오류율이 급격히 상승한다는 점을 확인했으며, 이는 학습 에포크 수와의 상관관계가 있을 것으로 추정된다.
이 논문의 기여는 네 가지로 요약된다. (1) 대규모 DBN 학습을 위한 드롭아웃 기반 분산 프레임워크 설계, (2) GPU와 클러스터를 결합한 효율적인 구현, (3) 네 가지 모델 결합 전략 제시, (4) MNIST 실험을 통한 실용성 검증. 특히, 모델 병렬화와 드롭아웃을 동시에 활용함으로써 파라미터 수와 통신 부하를 동시에 감소시킨 점이 혁신적이다. 향후 연구에서는 더 복잡한 데이터셋(예: ImageNet)과 비동기식 업데이트의 수렴 특성을 이론적으로 분석하고, 파라미터 서버 대신 P2P 방식의 분산 합의를 도입해 확장성을 더욱 높이는 방안을 탐색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기