고대인류 DNA 연구 데이터 공유 성공 비결
초록
본 연구는 1988년부터 2013년까지 발표된 고대인류 DNA 논문 162편을 대상으로 미토콘드리아, Y‑염색체 및 상염색체 다형성 데이터의 공유 현황을 분석한다. 전체 데이터의 97.6 %가 재사용 가능 형태로 제공되었으며, 이는 진화·의료·법의학 유전학 분야보다 현저히 높은 수치이다. 설문 조사 결과, 연구자들의 투명성·개방성에 대한 인식이 높은 공유율을 이끌어낸 주요 동인으로 작용함을 확인하였다. 데이터는 주로 본문에 삽입되는 형태였지만, 완전한 미토콘드리아 서열 및 차세대 시퀀싱(NGS) 적용 시 공용 데이터베이스 활용이 증가하였다. 연구자는 동기 부여, 정책·규범, 데이터 제공 방식의 최적화가 고대 DNA 연구에서 열린 과학을 구현하는 핵심 요소임을 강조한다.
상세 분석
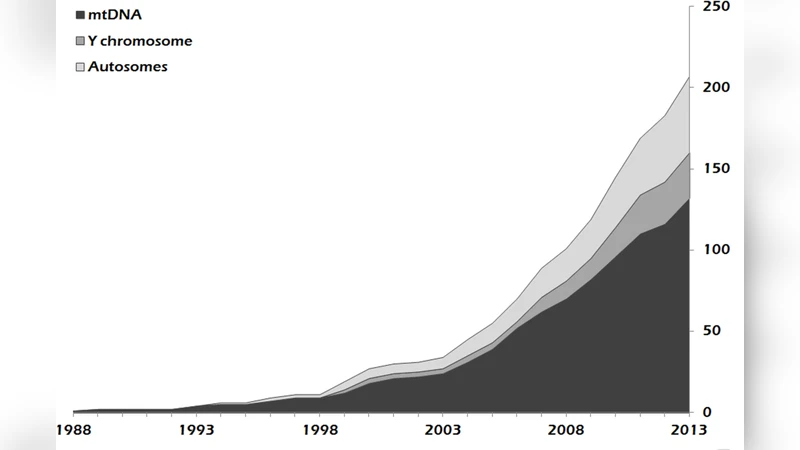
이 논문은 고대인류 DNA 연구 분야가 데이터 공유 측면에서 다른 유전학 분야를 앞서는 사례로서, 왜 그러한 높은 공유율이 가능한지를 다각도로 탐구한다. 먼저 162편의 논문을 체계적으로 수집·분류하여, 미토콘드리아, Y‑염색체, 상염색체 각각의 데이터 유형별 공유 비율을 산출하였다. 전체 공유율은 97.6 % ± 2.1 %로, 이는 기존 문헌에서 보고된 진화유전학(≈70 %), 의료유전학(≈55 %), 법의학유전학(≈45 %)에 비해 현저히 높은 수치다. 데이터 제공 방식은 크게 세 가지로 구분되었다: (1) 본문 텍스트 혹은 보조표에 직접 삽입, (2) 보조 파일(예: Excel, CSV) 형태, (3) 공용 데이터베이스(NCBI GenBank, EMBL‑EBI 등)에 등록. 초기 연구(1990년대 초반)에서는 본문 삽입이 주를 이루었으나, 2000년대 중반 이후 차세대 시퀀싱(NGS) 기술이 도입되면서 대용량 서열 데이터를 효율적으로 관리·공유하기 위해 데이터베이스 활용이 급증하였다.
동기 요인 분석을 위해 저자들을 대상으로 설문을 실시했으며, 응답자는 ‘연구 투명성 확보’, ‘재현 가능성 향상’, ‘학문적 신뢰도 증대’를 가장 중요한 공유 동기로 꼽았다. 특히 고대 DNA는 시료 확보가 어렵고 오염 위험이 크기 때문에, 결과 검증을 위해 원시 데이터의 공개가 필수적이라는 인식이 강하게 나타났다. 반면, 정책·규범 측면에서는 주요 학술지와 연구기관이 데이터 공유를 명시적으로 요구하거나, 연구비 지원 시 데이터 관리 계획(DMP)을 제출하도록 하는 제도가 공유율을 유지하는 데 보조적인 역할을 한다는 점을 확인했다.
이러한 결과를 바탕으로 저자는 데이터 공유를 촉진하기 위한 세 가지 실천적 제안을 제시한다. 첫째, 연구자 개인의 ‘오픈 사이언스 마인드’를 강화하기 위한 교육 및 인센티브 제공, 둘째, 데이터베이스 표준화와 메타데이터 품질 관리 체계 구축, 셋째, 데이터 보존 및 장기 접근성을 보장하는 인프라 투자이다. 고대 DNA 연구는 실험적 난이도가 높음에도 불구하고, 투명한 데이터 제공이 학문적 진보와 신뢰 구축에 결정적임을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기