과학 저널의 계층적 네트워크 분석
초록
이 논문은 1975‑2011년 사이 Web of Science에 등재된 35백만 건의 논문과 13 202개의 학술지를 대상으로, 인용 네트워크를 이용해 저널 간의 계층 구조를 두 가지 방법으로 구축한다. 첫 번째는 m‑reach 중심성을 활용한 흐름 계층이며, 두 번째는 자동 태그 계층 추출 기법을 적용한 중첩 계층이다. 두 계층은 전반적으로 일치하지만, 세부적인 위치 차이가 존재함을 보여준다.
상세 분석
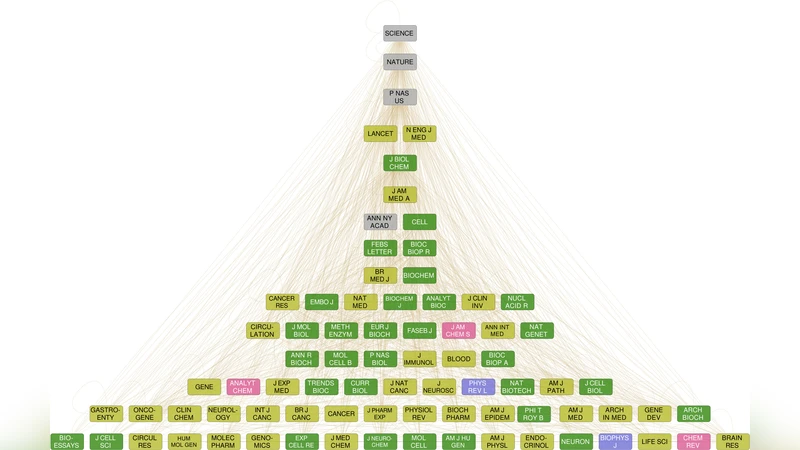
본 연구는 학술지 간 인용 관계를 정교히 모델링함으로써 기존의 단일 지표(예: 임팩트 팩터) 한계를 극복하고, 다차원적인 영향력을 평가한다. 흐름 계층은 ‘m‑reach centrality’를 기반으로 하며, 여기서 m은 최대 경로 길이(논문에서는 m=3을 최적값으로 선정)이다. 인용 네트워크의 방향을 역전시켜, 한 저널에 실린 논문이 다른 논문에 의해 몇 단계까지 도달될 수 있는지를 측정한다. Cₘ(J)는 저널 J에서 시작해 m단계 이내에 도달 가능한 외부 논문 수이며, 값이 클수록 해당 저널은 네트워크 상에서 ‘상위’에 위치한다. 이 방법은 저널이 발표한 논문의 양과 질에 관계없이, 실제 지식 확산 효율을 반영한다는 점에서 기존 인용 횟수 기반 지표와 차별화된다.
중첩 계층은 Tibély 등(2013)의 자동 태그 계층 추출 알고리즘을 변형하여 적용하였다. 저널을 ‘태그’라 보고, 인용 네트워크에서 공동 등장 빈도와 포함 관계를 분석해, 상위‑하위 구조를 재귀적으로 구성한다. 결과적으로 다학제적 저널이 최상위에 배치되고, 특정 분야에 특화된 저널이 하위 가지로 전개된다.
두 계층을 비교했을 때, 전반적인 위계는 유사하지만, 흐름 계층에서는 정보 전파 효율이 높은 저널(예: Nature, Science, Cell)이 최상위에 오르는 반면, 중첩 계층에서는 학문적 포괄성이 높은 저널이 우선시된다. 또한, 회의록·기술 보고서와 같이 인용이 적은 출판물은 두 계층 모두 하위에 위치한다는 점이 확인되었다.
데이터 전처리 단계에서 저자는 11자리 약어 필드를 사용해 저널을 식별했으며, 이는 연도·권·호 정보가 포함된 전체 명칭보다 일관성이 높았다. 또한, 저널 간 직접 인용이 아닌 논문 수준 인용을 이용함으로써 ‘메모리 효과’(특정 분야 논문이 동일 분야 내에서 재인용되는 경향)를 보존하고, 저널 집계 시 발생할 수 있는 왜곡을 최소화했다.
한계점으로는 m값 선택에 따른 민감도, 인용 데이터의 시간적 편향(최근 논문이 과대평가될 가능성), 그리고 저널 자체의 정책 변화(예: 오픈 액세스 전환) 등이 있다. 보완 연구로는 동적 계층 변화 추적, 분야별 m‑reach 최적화, 그리고 다른 데이터베이스(Scopus, PubMed)와의 비교가 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기